While I use the Brave web browser, I don’t access the social media site formerly known as Twitter with it, so I haven’t seen the described behaviour, thank goodness:
Recent algorithm changes on X may be unfairly hammering Brave users. And there’s a larger issue here about bad interactions between robots and privacy measures.
@nikitabier
@brave
My friend Jay Maynard, who some of you may know as Tron Guy, just got permabanned off X for “inauthentic behavior”. His appeal was swiftly denied.
Jay is not a spammer, scammer or engagement farmer; he is, in fact, exactly the kind of good citizen X says it wants. Jay asked Gemini for analysis, and now thinks he knows what happened.
Brave, as a privacy measure, randomly changes the identity presented to sites in order to avoid tracking by the ad vampires. Gemini suggested that some code at X interpreted this as spammy behavior using multiple browsers. If so – and this does seem plausible – everybody trying to protect their privacy with Brave is at risk.
This is a general problem, not just an X glitch or a Brave issue. Social media sites are increasingly relying for security on forms of heuristic AI that are prone to unacceptably high false-positive rates.
More specifically, platforms are increasingly treating a user’s refusal to be tracked, fingerprinted, and categorized as a hostile act. When a site makes it impossible to connect via a privacy-focused user agent without getting flagged as a malicious bot, it stops being “security” and effectively becomes a retaliatory lockout for protecting oneself.
Worse yet, such system architecture provides no circuit breaker – humans are only rarely and exceptionally asked review for errors. Jay’s appeal denial came back so fast that it was obvious no meat-brain ever saw it. He has filed complaints within the Minnesota Attorney General and the Better Business Bureau, because what else can he do? The robots have locked him out.
Badly designed robots and zeal to squeeze human oversight out of the system forces regular citizens to rely on state law enforcement or consumer protection bureaus.
Allow me to gently suggest to the people running X that unless you want politicians poking their noses into your business and imposing constraints on you that you are not going to like, you need to fix your security and appeal processes so running to the law isn’t necessary.
Comments Off on Brave browser users and X’s latest algorithm changes
On his Substack, Brian Lilley points out another glaring inconsistency between Prime Minister Mark Carney’s rah-rah pro-Canadian rhetoric and his anti-Canadian actions:
This story should outrage everyone, regardless of political stripe.
But considering the positions taken by progressive Liberals in this country concerning Donald Trump, it should really outrage them. Sadly, like with Trudeau or whichever politician people seem to support these days, Carney’s backers won’t see the error of his ways.
When I was a young army cadet, the first person I would see checking into the James Street Armouries in Hamilton — now known as the John Weir Foote Armoury after a ceremony I was part of in 1990 — well, the first person I would see would be the Commissionaire. Back in the mid-80s these were mostly people who were veterans of the Korean War or our peacekeeping missions who were now charged with providing security at federal buildings.
Founded in 1925 to give meaningful employment to veterans of the First World War, the Corps of Commissionaires has been providing security services at federal buildings, and others, for just over 100 years. Since shortly after the Second World War, the Commissionaires have had a special relationship with the federal government when it comes to providing security.
Just recently, the Carney government — the Elbows Up and Canada Strong folks — ended the arrangement that gave the Commissionaires first right of refusal on security at federal department buildings. They ended the agreement with the not-for-profit organization that is still the biggest employer of veterans in the country at the behest of a global company scooping up security contracts from the Trump admin including ICE detention centres like Alligator Alcatraz.
You can love Trump or hate him but don’t tell me you are Elbows Up, that we are experiencing a rupture, that the old relationship is over, that being close to the Americans is dangerous and then do this.
I detailed it all in my latest column for the Toronto Sun including who was behind this, how it went down, and why it is outrageous.
The Canadian Corps of Commissionaires was eventually founded in 1925, specifically to employ Canadian veterans of the First World War. We were initially established in Montreal, then Toronto and Vancouver, to look after these men and women and provide them with transitional and permanent jobs, primarily in the security field. The Right Honourable John Buchan, Governor General of Canada, became the Corps’ first patron in 1937. Viceregal patronage has been an 81-year tradition since then.
In the early years, we mostly provided guarding services for government institutions. From 1925 to 1948, Commissionaires expanded throughout Canada.
In 1950, with the opening of the St. John’s, Newfoundland division, Commissionaires was operating services from coast to coast.
By 1982, Commissionaires exceeded 10,000 employees.
Comments Off on Carney elbows out Canadian veterans to support an American company
I haven’t been following the latest attempt to assassinate the President, but Mark Steyn apparently has been (even though he’s touring Ukraine at the moment):
By contrast Washington is ever more like Churchill’s riddle wrapped in a mystery inside an enigma. My conscience is clear. Almost two years ago, it was perfectly obvious to anyone who examined the facts on the ground in Butler, Pennsylvania that the United States Secret Service had an institutionalised level of incompetence and/or malevolence that was assisting those many persons anxious to kill Trump to do so. Even as mere incompetence, it is murderously so: Corey Comperatore is dead, and everyone in Butler and DC who enabled his death still has a job.
So immediately afterwards I stated the obvious:
Instead, the 47th President promoted the chap in charge in Butler that day to head of the entire Secret Service: one Sean Curran. And, on Saturday night, Mr Curran allowed the same thing that happened at Butler to happen all over again. On the incompetence front, look again at the would-be assassin breaching security with his brilliant cunning plan, requiring months of painstaking training and preparation and attention to detail, of simply running through the checkpoint:
The chaps at Kharkiv railway station are more alert than those guys. Yet setting aside the under-performance of the individual agents — close enough for government work, it seems — this ingenious manoeuvre became a critical issue mainly because, exactly as at Butler, the Secret Service had taken the decision to shrink the perimeter of the “secure zone”. In Islamabad the other day, the Pakistanis were hopeful that Vance and the Iranians would be jetting in for another round of face-to-face negotiations. So they took the precaution of ordering all the other guests out of the designated hotel: the Tehran delegation, in particular, is concerned that Netanyahu will off them while they’re in town by having Mr Moshe Wetwork check in to the junior suite on the fifth floor.
No such worries at the grisly Washington Hilton — even though half the country would be cheering on Mr Wetwork. On ABC TV, Jimmy Kimmel threw a Thursday-night “alternative” White House Correspondents Dinner at which he saluted the First Lady:
You have the glow of an expectant widow.
I have never knowingly watched Jimmy Kimmel or Jimmy Fallon or Jimmy Colbert, whichever is which. But I’m old enough to remember when Johnny Carson in 1981 told Nancy Reagan and indeed when Steve Allen in 1901 told Ida McKinley that they had the glow of expectant widows.
Oh, wait, no. Neither Johnny nor Steve did that. Because, back in 1981 and 1901, America still had sufficient of what the late Roger Scruton called the “pre-political we” to recognise that assassination fantasies are not helpful to a functioning polity.
Alas, the role that in other western nations has to be outsourced to Muslim rape gangs and low-IQ child-stabbers and sundry novelty demographics is in America performed by showbiz bigshots, NPR ladies d’un certain âge, and pajama boys with a quarter mil in college debt.
That, however, is a given. What ought not to be a given is that the Secret Service is on their side. At Butler, Mr Curran and his colleagues shrunk the perimeter so that it excluded an easily accessible roof with a clear line to Trump’s head. At the Washington Hilton, Mr Curran and his colleagues shrunk the perimeter to the event room and its immediate approach. In the usual tedious “manifesto”, the would-be killer nevertheless noted that the security was so “insanely” bad they must be “pranking” him:
What the hell is the Secret Service doing..?
Like, I expected security cameras at every bend, bugged hotel rooms, armed agents every 10 feet, metal detectors out the wazoo.
What I got (who knows, maybe they’re pranking me!) is nothing.
No damn security.
Not in transport.
Not in the hotel.
Not in the event.
Like, the one thing that I immediately noticed walking into the hotel is the sense of arrogance. I walk in with multiple weapons and not a single person there considers the possibility that I could be a threat.
The security at the event is all outside, focused on protestors and current arrivals, because apparently no one thought about what happens if someone checks in the day before.
Like, this level of incompetence is insane, and I very sincerely hope it’s corrected by the time this country gets actually competent leadership again.
Like, if I was an Iranian agent, instead of an American citizen, I could have brought a damn Ma Deuce in here and no one would have noticed shit.
Actually insane.
So, once he’d run through the security line, he was able to get into the same men’s room that the entire cabinet had to use. Had RFK or Pete Hegseth felt the urge before settling in for a night of long speeches, the headlines this weekend would have been very different. Half the presidential line of succession was in there. That’s what the geopolitical types call, if you remember, a “decapitation strategy”. Except you don’t need a bunker buster, just some California doofus willing to take a run at the checkpoint — and bingo, whoever the Secretary of the Interior is winds up like some z-list ayatollah.
On a lighter note, Daniel Jupp imagines what Trump-haters might be thinking in the wake of another progressive would-be assassin’s attempt:
MAINSTREAM media and politicians throughout the Western world who insist on calling Trump a fascist, a dictator, a threat to democracy, and literally Hitler, declared a three-hour moratorium on insulting him before they raced to try to escape any responsibility.
“Our thoughts and prayers go out to President Trump and his family while we write an article claiming the assassin is a Republican and it’s actually Trump’s fault”, announced the BBC. “Our viewers should be reassured that we ARE doctoring footage.”
“Violence has no place in politics when it fails”, Ed Davey, leader of Britain’s Liberal Democrats intoned.
Religious leaders condemned the rise of populism and white supremacy that fuels such attacks.
“We must have unity, Christian compassion even for those who don’t deserve it, and come together in kindness. He who lives by the sword dies by the sword at some point”, Pope Leo wisely reflected.
“Where is this violence coming from?” wailed the Associated Press. The news agency issued a statement reminding people that assassinations should be attempted only in settings where misses, ricochets and other deaths could not possibly include any of their journalists. “A Correspondents’ Dinner is simply not the place for this sort of thing.”
On the social media site formerly known as Twitter, ESR discusses a pre-computer (pre-electronics) proof that open source is more secure than closed source:
“How university open debates and discussions introduced me to open source” by opensourceway is licensed under CC BY-SA 2.0
There’s an old, bad idea that’s been trying to resurrect itself on X in the last couple of days. Which makes it time for me to explain exactly why, in the age of LLMs, open-sourcing your code is an even more important security measure than it was before we had robot friends.
The underlying principle was discovered in the 1880s by an expert on military cryptography, a man named August Kerckhoffs, writing long before computers were a thing.
To start with, you need to focus in on the fact that cryptosystems have two parts. They have methods, and they have keys. You feed a key and a message to a method and get encrypted information that, you hope, only someone else with the same pair of method and key can read.
What Kerckhoffs noticed was this: military cryptosystems in normal operation leak information about their methods. Code books and code machines get captured, stolen, betrayed, or lost in simple accidents and found by people you don’t want to have them. This was the pre-computer equivalent of an unintended source-code disclosure.
Cryptosystems also leak information about their keys — think post-it notes with passwords stuck to a monitor. What Kerckhoffs noticed is that these two different kinds of compromising leakage happen at very different base rates. It is almost impossible to prevent leakage of information about methods, but just barely possible to prevent leakage of information about keys.
Why? Keys have fewer bits. This makes them easier to keep secret.
Remember: this was something an intelligent man could notice in the 1880s, well before even vacuum tubes. Which is your first clue that the power of this observation hasn’t changed just because we’re in the middle of a freaking Singularity.
Security through obscurity — closed source code — means you’re busted if either the source code or the keys get leaked. Open source is a preemptive strike — it’s a way to force the property that your security depends *only* on keeping the keys secret.
What you’re doing by designing under the assumption of open source is preventing source code leakage from being a danger. And that’s the kind of leakage with a high base rate.
As far back as 1947 Claude Shannon applied this to electronic security — he did critical work on the voice scramblers that were used for secure telephone communications between heads of state during World War II. Shannon said one should always design as though “the enemy knows the system”. The US’s National Security Agency still uses this as a guiding principle in computer-based cryptosystems.
If you’re doing software security, always design as though the enemy can see your source code. I’m still a little puzzled that I was apparently the first person to notice that this was a general argument for open source; as soon as I did, my first thought was more or less “Duh? Somebody should have noticed this sooner?”
Now let’s consider how LLMs change this picture. Or…don’t.
An LLM is like a cryptanalyst with a superhuman attention span that never sleeps. If your system leaks information that can compromise it, that compromise is going to happen a hell of a lot faster than if your adversary has to rely on Mark 1 meatbrains.
But it gets worse. With LLMs, decompilation is now fast and cheap. You have to assume that if an adversary can see your executable binary, they can recover the source code. If you were relying on that to be secret, you are *screwed*.
Leakage control — limiting the set of bits that can yield a compromise — is more important than ever. So security by code obscurity is an even more brittle and dangerous strategy than it used to be.
Anybody who tries to tell you differently is either deeply stupid or trying to sell you something that you should not by any means buy.
Comments Off on Another proof of the value of open source
Melanie in Saskatchewan explains why the constant Liberal talking point that refusing to get a particular security clearance “proved” that Pierre Poilievre was next-door to a traitor will probably not be raised any more:
Image from Melanie in Saskatchewan
Open Letter to Canada’s Security Clearance Scolds: Carney Just Proved Pierre Right!
To every Liberal and NDP partisan who has spent the last year yelling “security clearance” like it is a magic spell that turns criticism into treason, congratulations. Mark Carney just demonstrated Pierre Poilievre’s point for him, on camera, in real time.
The moment came on March 3, 2026, during Prime Minister Mark Carney’s Indo-Pacific trip. After meetings in India with Prime Minister Narendra Modi, Carney held a press availability with Canadian media while travelling through the region. The topic journalists wanted clarified was not subtle. They asked about foreign interference linked to India and the 2023 assassination of Sikh activist Hardeep Singh Nijjar in Surrey, British Columbia, the allegation that detonated Canada’s diplomatic crisis with India.
The question came from Dylan Robertson of The Canadian Press during the media scrum. He asked directly whether Carney believed India continued to engage in foreign interference or transnational repression targeting Canadians.
Carney swerved. He was asked again. And again.
Eventually, after the careful circling that seasoned politicians deploy when a straight answer would be inconvenient, he landed on the tell. Not the kind you need a polygraph for. The kind you publish in a civics textbook.
Here is what he said, exactly:
There will not be consequences for those officials … There are aspects of those briefings that I can’t share in public, and I’m not going to betray them. I will tell you that there is progress on these issues.
Read that again, slowly, with a spoon handy in case you choke on the irony. Because this is the whole debate in one neat little ribbon.
Pierre Poilievre’s argument, from the start, has been that the particular classified briefings being pushed would place him inside a legal box. Once inside it, the rules governing those briefings restrict what he can say publicly and how he can use the information while doing his job as Leader of the Opposition. Global News reported Poilievre’s office saying officials told them the briefing structure could leave him legally prevented from speaking publicly about certain information except in narrow ways, which they argued would “render him unable to effectively use any relevant information he received”.
Now watch what just happened.
Carney, the man with the clearance and the briefings, is asked direct questions about one of the most explosive foreign-interference files in modern Canadian politics.
And his answer, translated into plain English, is simple: I cannot share what I know.
Comments Off on The “security clearance issue” demonstrated by, of all people, Mark Carney
Domestic terrorists got into RAF Brize Norton, one of Britain’s main airbases, last week and committed damage that may range into the tens of millions of pounds … and were in and out with the RAF none the wiser:
So this was a serious attack; it’s also an intensely embarrassing one. The terrorists got in and out completely undetected; it appears nobody at Brize Norton was aware of the attack until the perpetrators had already escaped. This would be bad enough if they’d been Spetsnaz-trained infiltrators, flitting silently from shadow to shadow towards their targets. In fact, however, they were a couple of unwashed hippies from Palestine Action, and they “infiltrated” the base on electric motorbikes. It is absolutely staggering that they were able to get in, attack two valuable aircraft and then get out again without being intercepted.
Or maybe it isn’t. This is the station commander of RAF Brize Norton:
Gp Capt Henton appears to have spent her entire career in non-operational roles. She also seems to have some very strange ideas about concepts such as masculinity and even patriotism. In a paper she wrote (which is available online) Henton appears strongly critical of traditional military culture, particularly that in the combat units she has never been part of. Is it just coincidence that, under the command of someone who is effectively an HR manager in a uniform, traditional military concerns such as security appear to have been badly neglected?
It’s undeniable that security at Brize Norton was neglected. One of the things I was trained in, as an Intelligence Corps operator, was protective security. We tended to focus on the protection of classified information, but the same principles apply to the protection of anything else (for example aircraft), and one of those principles is that if the security around an asset is weak in one respect — for example, physical barriers like fences — you can plug that gap by deploying other assets — for example, guards.
I used Google Street View to do a perimeter recce of Brize Norton, and took this screenshot looking from Station Road at the eastern end of the base’s runway:
This shot is taken from a public road, outside the base. The only perimeter security is a simple, easily climbed wooden fence less than six feet high. For a long stretch it has no “topping” — security jargon for razor wire or other anti-climb obstacles. There is also no perimeter security lighting along this section of the road. There aren’t even streetlights on the road itself. This is a massive weakness in physical security, which any terrorist can easily identify using open-source tools like Google Street View. The red ellipse I have drawn on the image highlights aircraft — seven of them, a mix of Voyagers and A400M transports — parked on the apron. They are less than three-fifths of a mile (900m in new money) from the perimeter fence, a distance that an electric scooter can cover in around 90 seconds. This level of physical security is completely unacceptable for the protection of such valuable assets, so it should have been supplemented with armed guards. It wouldn’t take all that many. A twelve-man guard under the command of a corporal could easily supply a pair of two-man prowler patrols, one on the apron and one randomly checking vulnerable points around the perimeter. That would have been enough to intercept and stop this attack.
Comments Off on RAF Brize Norton apparently had almost no security for its planes at all
From Tsarist Russia to Stalin and the Cold War, the Soviet secret police evolved through endless name changes — but their mission never wavered: repress, control, and terrify. Discover how these agencies — from the Okhrana to the Cheka, GPU, OGPU, NKVD, and eventually the KGB, shaped Soviet life with ruthless efficiency. Torture, purges, and mass surveillance weren’t just tactics; they were the system. (more…)
Comments Off on The Machine of Terror: How the Soviet Secret Police Ruled – W2W 32
A rare appearance of a Matt Gurney column outside the paywall at The Line explains why the Prime Minister couldn’t resist the temptation to attack Pierre Poilievre on the national security file, despite the fact that it gives Poilievre a strong counterattack:
Prime Ministers Starmer and Trudeau at the NATO summit in Washington. Image from Justin Trudeau’s X account.
What Justin Trudeau did on Wednesday from the witness standing at the foreign interference inquiry — when he made his dramatic announcement of having seen a list of Conservatives who are compromised by or vulnerable to foreign interference — makes a kind of sense.
It does. It was an effective attack on Pierre Poilievre, who has stubbornly led with his chin for months. The reaction of many of my Conservative friends was telling. They knew Trudeau landed a hit, and they were pissed. They were ready for it — I think their counterattack was as good or better. But this whole story, or at least this little snippet of it, starts with Trudeau taking a swing, and not missing.
[…]
In that context, Trudeau’s decision to tease the possibility of some unnamed Conservatives being involved in the machinations of foreign interference makes sense. He saw Poilievre’s chin and decided to shove his fist into it. It’s politics. I get it.
But, once again, I’m not sure that the PM thought this through all the way. Our PM has a habit of occasionally letting his combative instincts get the better of him. The man has a weakness for showy, dramatic gestures, and loves to try and seize the big moments. Sometimes they blow up in his face. I think this one will, too. It is, I suspect, less a punch to the face, and more of an elbow-to-the-boob. It’ll cause more problems than the gesture was worth.
[…]
Trudeau doesn’t get a lot of opportunities to look like a tough leader these days, and he got two this week. His eviction of six Indian diplomats that Canadian intelligence believes were involved in guiding violent crimes in Canada, aimed at politically connected members of Canada’s large Indian diaspora, was one (and I am not yet cynical enough to believe the timing was politically motivated). The second, of course, was Trudeau’s bombshell testimony. Given the shellacking he’s been taking of late, it probably felt amazing [to] go on the attack yesterday.
The problem for the prime minister is that, today, having had his dramatic moment, there’s no follow through. He dropped the mic and then Poilievre did what he was always and obviously going to do: the opposition leader picked that mic right back up again and started talking into it.
My message to Justin Trudeau is: release the names of all MPs that have collaborated with foreign interference. But he won’t. Because Justin Trudeau is doing what he always does: he is lying. He is lying to distract from a Liberal caucus revolt against his leadership and revelations he knowingly allowed Beijing to interfere and help him win two elections. … If Justin Trudeau has evidence to the contrary, he should share it with the public. Now that he has blurted it out in general terms at a commission of inquiry — he should release the facts. But he won’t — because he is making it up.
If Poilievre’s decision to forgo a security clearance is overly complicated and technocratic, then Trudeau’s decision to attack him for it suffers the same drawbacks. By comparison, Poilievre’s approach, here, is better, simpler, and most crucially, it’s right: Release the names!
If MPs from any party have been compromised, the public deserves to know.
I don’t say that lightly or impulsively. There are absolutely downsides to releasing the names, including the very real risks to compromising our investigations and destroying the reputations of people who may have committed no crime. This sucks. But there are greater downsides to not releasing the names — until the Canadian public knows them, our entire democratic system is suspect. To put it another way, if it is inappropriate to release the names in full, then it is equally if not more inappropriate for a prime minister to publicly tease those names during his testimony, while hiding behind oaths of national security in order to avoid handing over the receipts. Protections of “national security” are intended to protect real sources and reputations — not to serve as a launchpad to lob allegations at foes while dodging accountability and transparency.
Comments Off on Justin Trudeau “has, yet again, outsmarted himself for the short-term win”
“I Hear You wiretapping poster, Mad Magazine, NYC” by gruntzooki is licensed under CC BY-SA 2.0 .
For as long as law enforcement has sought a way to monitor people’s conversations — though they’d only do so with a court order, we’re supposed to believe — privacy experts have warned that building backdoors into communications systems to ease government snooping is dangerous. A recent Chinese incursion into U.S. internet providers using infrastructure created to allow police easy wiretap access offers evidence, and not for the first time, that weakening security for anybody weakens it for everybody.
Subverted Wiretapping Systems
“A cyberattack tied to the Chinese government penetrated the networks of a swath of U.S. broadband providers, potentially accessing information from systems the federal government uses for court-authorized network wiretapping requests,” The Wall Street Journal reported last week. “For months or longer, the hackers might have held access to network infrastructure used to cooperate with lawful U.S. requests for communications data.”
While the Journal report doesn’t specify, Joe Mullin and Cindy Cohn of the Electronic Frontier Foundation (EFF) believe the wiretap-ready systems penetrated by the Chinese hackers were “likely created to facilitate smooth compliance with wrong-headed laws like CALEA”. CALEA, known in full as the Communications Assistance for Law Enforcement Act, dates back to 1994 and “forced telephone companies to redesign their network architectures to make it easier for law enforcement to wiretap digital telephone calls,” according to an EFF guide to the law. A decade later it was expanded to encompass internet service providers, who were targeted by Salt Typhoon.
“That’s right,” comment Mullin and Cohn. “The path for law enforcement access set up by these companies was apparently compromised and used by China-backed hackers.”
Ignored Precedents
This isn’t the first time that CALEA-mandated wiretapping backdoors have been exploited by hackers. As computer security expert Nicholas Weaver pointed out for Lawfare in 2015, “any phone switch sold in the US must include the ability to efficiently tap a large number of calls. And since the US represents such a major market, this means virtually every phone switch sold worldwide contains ‘lawful intercept’ functionality.”
Comments Off on Government-mandated backdoor access – “weakening security for anybody weakens it for everybody”
J.D. Tuccille explains the real reason the French government arrested Pavel Durov, the CEO of Telegram:
It’s appropriate that, days after the French government arrested Pavel Durov, CEO of the encrypted messaging app Telegram, for failing to monitor and restrict communications as demanded by officials in Paris, Meta CEO Mark Zuckerberg confirmed that his company, which owns Facebook, was subjected to censorship pressures by U.S. officials. Durov’s arrest, then, stands as less of a one-off than as part of a concerted effort by governments, including those of nominally free countries, to control speech.
“Telegram chief executive Pavel Durov is expected to appear in court Sunday after being arrested by French police at an airport near Paris for alleged offences related to his popular messaging app,” reported France24.
A separate story noted claims by Paris prosecutors that he was detained for “running an online platform that allows illicit transactions, child pornography, drug trafficking and fraud, as well as the refusal to communicate information to authorities, money laundering and providing cryptographic services to criminals”.
Freedom for Everybody or for Nobody
Durov’s alleged crime is offering encrypted communications services to everybody, including those who engage in illegality or just anger the powers that be. But secure communications are a feature, not a bug, for most people who live in a world in which “global freedom declined for the 18th consecutive year in 2023”, according to Freedom House. Fighting authoritarian regimes requires means of exchanging information that are resistant to penetration by various repressive police agencies.
“Telegram, and other encrypted messaging services, are crucial for those intending to organise protests in countries where there is a severe crackdown on free speech. Myanmar, Belarus and Hong Kong have all seen people relying on the services,” Index on Censorship noted in 2021.
And if bad people occasionally use encrypted apps such as Telegram, they use phones and postal services, too. The qualities that make communications systems useful to those battling authoritarianism are also helpful to those with less benign intentions. There’s no way to offer security to one group without offering it to everybody.
As I commented on a post on MeWe the other day, “Somehow the governments of the west are engaged in a competition to see who can be the most repressive. Canada and New Zealand had the early lead, but Australia, Britain, Germany, and France have all recently moved ahead in the standings. I’m not sure what the prizes might be, but I strongly suspect “a bloody revolution” is one of them (if not all of them).”
Comments Off on Pavel Durov’s arrest isn’t for a clear crime, it’s for allowing everyone access to encrypted communications services
Glenn “Instapundit” Reynolds on one of the biggest yet least recognized issues of most modern nations — our overall declining institutional competence:
Almost everywhere you look, we are in a crisis of institutional competence.
The Secret Service, whose failures in securing Trump’s Butler, PA speech are legendary and frankly hard to believe at this point, is one example. (Nor is the Butler event the Secret Service’s first embarrassment.)
The Navy, whose ships keep colliding and catching fire.
Major software vendor Crowdstrike, whose botched update shut down major computer systems around the world.
The United States government, which built entire floating harbors to support the D-Day invasion in Europe, but couldn’t build a workable floating pier in Gaza.
And of course, Boeing, whose Starliner spacecraft is stuck, apparently indefinitely, at the International Space Station. (Its crew’s six-day mission, now extended perhaps into 2025, is giving off real Gilligan’s Island energy.) At present, Starliner is clogging up a necessary docking point at the ISS, and they can’t even send Starliner back to Earth on its own because it lacks the necessary software to operate unmanned – even though an earlier build of Starliner did just that.
Then there are all the problems with Boeing’s airliners, literally too numerous to list here.
Roads and bridges take forever to be built or repaired, new airports are nearly unknown, and the Covid response was extraordinary for its combination of arrogant self-assurance and evident ineptitude.
These are not the only examples, of course, and readers can no doubt provide more (feel free to do so in the comments) but the question is, Why? Why are our institutions suffering from such widespread incompetence? Americans used to be known for “know how,” for a “can-do spirit”, for “Yankee ingenuity” and the like. Now? Not so much.
Americans in the old days were hardly perfect, of course. Once the Transcontinental Railroad was finished and the golden spike driven in Promontory, Utah, large parts of it had to be reconstructed for poor grading, defective track, etc. Transport planes full of American paratroopers were shot down during the invasion of Sicily by American ships, whose gunners somehow confused them for German bombers. But those were failures along the way to big successes, which is not so much the case today.
But if our ancestors mostly did better, it’s probably because they operated closer to the bone. One characteristic of most of our recent failures is that nobody gets fired. (Secret Service Director Kim Cheatle did resign, eventually, but nobody fired her, and I think heads should have rolled on down the line).
Peter Jacobsen discusses the July technical and financial fiasco as a faulty software patch from CrowdStrike took down huge segments of the online economy and how regulatory capture may explain why the outage was so widespread:
“CrowdStrike outage at Woolworths in Palmerston North” by Kiwi128 is marked with CC0 1.0 .
On July 19th, something peculiar struck workers and consumers around the world. A global computer outage brought many industries to a sudden halt. Employees at airports, financial institutions, and other businesses showed up to work only to find that they had no access to company systems. The fallout of the outage was huge. Experts estimate that it totaled businesses $5 billion in direct costs.
The company responsible, CrowdStrike, was also severely impacted. Shareholders lost about $25 billion in value, and some are suing the company. The outage has led to expectations of, and calls for, stricter regulations in the industry.
But how did the blunder of one company lead to such a massive outage? It turns out that the supposed solution of “regulation” may have been one of the primary culprits.
Regulatory Compliance
CrowdStrike, ironically, is a cybersecurity firm. In theory, they protect business networks and provide “cloud security” for online cloud computing systems.
Cloud security, in and of itself, is likely a service that businesses would demand on the market, but the benefit of increased security isn’t the only reason that businesses go to CrowdStrike. On their own website, the company boasts about one of its most important features: regulatory compliance.
[…]
When experts who have relationships with companies are called in to help write regulations, they may do so in a way favorable to industry insiders rather than outsiders. Thus, regulation is “captured” by the subjects of regulation.
We can’t say with certainty that this particular outage is the result of an intentional regulatory capture by CrowdStrike, but it seems clear that CrowdStrike’s dominance is, at least in part, a result of the regulatory environment, and, like most large tech companies, they’re not afraid to spend money lobbying.
In any case, without cumbersome regulations, it’s unlikely that cybersecurity would take on such a centralized form. Despite this, as is often the case, issues caused by regulation often lead to more calls for regulation. As economist Ludwig von Mises pointed out:
Popular opinion ascribes all these evils to the capitalistic system. As a remedy for the undesirable effects of interventionism they ask for still more interventionism. They blame capitalism for the effects of the actions of governments which pursue an anti-capitalistic policy.
So despite the reflexive call for regulation that happens after any disaster, perhaps the best way to avoid problems like this would be to argue that in terms of regulation, less is more.
Comments Off on The CrowdStrike outage and regulatory capture
Janice Fiamengo compares the iconic Trumpian reaction after being wounded by a sniper with the cries for diversity at all costs from others:
Donald Trump, surrounded by Secret Service agents, raises his fist after an attempt on his life during a campaign speech in Butler, PA on 13 July, 2024.
Many observers have had harsh words for the female Secret Service agents who performed poorly in response to the attempt on Trump’s life last Saturday (see this Wired article for a catalogue of the charges, in which the author cannot muster a single rebuttal). Some noted that Trump’s security detail for the Republican National Convention is now, it appears, exclusively male. And rightly so. There is no equality when bullets start to fly, and it is lethal to pretend there is.
When the first shot rang out, 50-year-old Pennsylvanian firefighter Corey Comperatore is reported to have done what men typically do in such situations: he shielded his wife and daughters, taking a bullet to the head. Women far more rarely perform such acts of self-sacrifice.
Comperatore lost his life because of a multitude of errors on the part of the Secret Service, including a long hesitation by snipers tasked with neutralizing threats. Video shows that at least one of these snipers, seemingly with the gunman in his sites, failed to take action until seconds after the gunman began firing. The agent seemed befuddled, scrambling back when the first shot came. Was he new on the job, inadequately trained, or sub-par in his skills? Or directed not to fire?
I am not equipped to answer these or the many other, darker, questions about the bungled security operation. What can be said for certain is that if some element of the Secret Service was not treasonously complicit in the attempt on Trump’s life, it was certainly massively inadequate to its task of protecting him and others at the rally. The gunman was allowed to gain access to his rooftop shooting position, and Trump was not extracted the moment the shooter’s presence became known.
Perhaps the women we saw in Trump’s security detail were new recruits helping Cheatle reach her target of 30% women by 2030. They looked amateur, panicked, and unpracticed. One of the women attempting to remove Trump from the stage was simply too small, and hesitant, for the task; she looked at one point as if she were engaged in a group hug at a United Church reconciliation ceremony. (As many have noted, her small stature enabled Trump’s fist-raised gesture of masculine defiance and his exhilarating “Fight! Fight! Fight!”). As Trump was being taken into the security vehicle, the four women surrounding the car looked jumpy and confused, scared and awkward. One woman was visibly unable to holster her gun.
I’ve never seen so many women guarding a former president, and I’ve never seen so many women obviously incapable.
We know that men and women have different strengths and aptitudes. Nearly a decade ago, the United States Marine Corps demonstrated through a year-long study of hundreds of Marines that even women who could pass the physical exam simply could not carry out standard military tasks as efficiently as men. The study found, unsurprisingly, that “The males were more accurate hitting targets, faster at climbing over obstacles, better at avoiding injuries.” The women struggled to carry weapons and ammunition, and even to use the weaponry properly. Women’s higher injury rate was marked: “The well documented comparative disadvantage in upper and lower-body strength resulted in higher fatigue levels of most women, which contributed to greater incidents of overuse injuries such as stress fractures.”
Comments Off on When diversity and competence requirements conflict
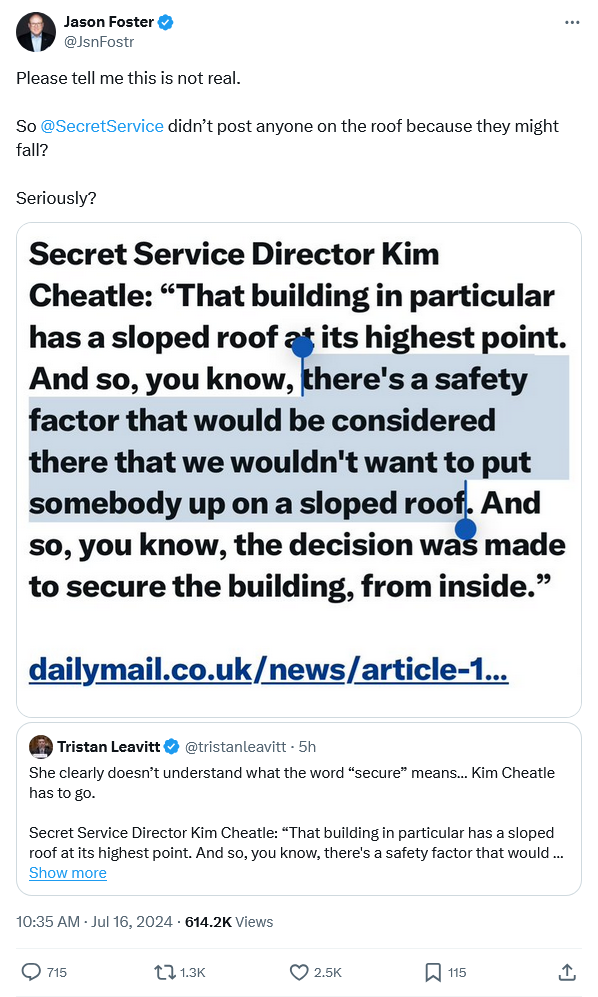
I haven’t been following every twist and turn of the post-assassination-attempt story, but this one really does have me scratching my head. According to the person who had the overall responsibility, the reason the shooter’s location was not properly secured was due to health and safety concerns … for the Secret Service agents, rather than the person they were supposed to be protecting:
Oddly, the roof that the counter-sniper team was occupying visually seems to have a steeper pitch than the one identified as too dangerous:
Since we’re looking at the biggest news event of the year (so far), let’s consider what N.S. Lyons calls “The World Spirit on a Golf Cart“:
I’m going to do something I normally resist doing and offer some hot take thoughts based on recent events. Not on the details of the attempted assassination of Donald Trump specifically (there’s already plenty of that out there), but on what feels like his role in our general moment in time.
In the minutes after Trump dodged a bullet on live television, I joked on Substack Notes that “one does not simply shoot Napoleon”. This proved open to misinterpretation in a few different directions, but what I meant was this:
Napoleon famously led from the front, charging time and again into a hail of bullets and cannon shot, and yet not once was he ever seriously injured. In fact his luck seemed so impervious that he quickly acquired a legendary aura of invincibility. This became part of his overwhelming charisma – meaning not just his social charm but the inexplicable sense of unstoppable destiny that he seemed to exude. This aura proved so captivating to normal men that when he escaped from exile and landed alone in France to … well let’s call it make his “reelection” bid, the army sent to stop him promptly surrendered and switched sides at the mere sight of him.
Napoleon had seemed to become something more than mere mortal: he was a living myth, a “man of destiny” whom Providence had handed some great role to play in history (for good or for ill) and who therefore simply couldn’t be harmed until that role had been fulfilled and the world forever changed. This is why when Hegel witnessed Napoleon he described him with awe as “the world-spirit on horseback”: he seemed truly an “epic” figure, the sweep of history seeming to have become “connected to his own person, [to] occur and be resolved by him” alone, one way or another.
This, it should be noted, used to be the standard way of explaining how the course of the world’s history was shaped. Thus was Alexander understood; thus was Caesar. Only after the Enlightenment and the onset of rationalistic modernity did this mythic view begin to wither away with the broader disenchantment of the world, to be replaced by a depersonalized and mechanistic view of historical causality.
We’re so back now though. Donald Trump has always been something of a bafflingly lucky man, as even his enemies are prone to admit. But witnessing him, in response to whatever whisper of Providence, tilt his head at precisely the right moment and degree to cheat death, I and it apparently many others can’t help but feel like he may be more than lucky – that he now seems as much myth as man.
And when he emerged, shaking off his bodyguards and streaked with blood, to stand and pump his fist in defiance beneath the American flag (as captured by a photographer who just happened to be there at the perfect place and time to reveal an era-defining symbolic image), this was rightly described by awed watchers in the stands and across the nation as “epic”. Maybe epic is the word that comes to their mind only because it’s become internet parlance for “cool shit”. But I suspect that they may mean more than that, that they may be attempting to describe the deeper charisma of someone who really seems to somehow have become a man of destiny, and that they intuited the scene as truly epochal in its meaning.
Donald Trump, surrounded by Secret Service agents, raises his fist after an attempt on his life during a campaign speech in Butler, PA on 13 July, 2024.
Earlier, Mark Steyn wondered whether the security failures in Butler were caused deliberately or through utter incompetence:
Let’s cut to the chase — the US Secret Service: In on it? Or just totally crap?
Well, I’ve thought the Secret Service were rubbish not just since we learned of the Cartagena hookers but for at least another decade before that. And increasingly, when it comes to American officialdom — from Kabul to Uvalde — to modify Henry Ford, you can get it in any colour as long as it’s bloated, lavishly over-funded and entirely dysfunctional.
And yet and yet … it’s hard to believe even these guys (plus their bevy of five-foot-two-eyes-of-blue Keystone chorus girls) could be this crap. Assuming for the purposes of argument that the body on the roof is actually that of the perp, a goofball barely out of high school hatched a plan to have Donald Trump’s head explode in close-up on live TV – and, wittingly or otherwise, the world’s most flush money-no-object security state did their best to help him pull it off.
In any accountable “public service”, the Secretary of Homeland Security and the Secret Service gal would already be gone. By this point after the Argentine invasion of the Falklands, Lord Carrington (Foreign Secretary), Sir Humphrey Atkins (Lord Privy Seal) and Richard Luce (Minister for Latin-American Affairs) had already resigned: see my column of September 17th 2001 expressing in my naïve Canadian way mystification as to why, six days later, all the 9/11 flopperoos had not been similarly dispatched.
Because that’s how it goes in the Republic of Non-Accountability, and, if he’s harbouring any doubts about his fitness for the job, Mayorkas figures it can wait till someone takes out RFK Jr. This is a depraved political culture.
What’s the old line? When seconds count, the police are minutes away? Not at a Secret Service event: even when the police are on site in massive overwhelming numbers, they’re still minutes away.
Comments Off on What do “‘elf an’ safety” concerns have to do with VIP protection details? A lot, it seems
Charles Stross wonders if Microsoft’s CoPilot+ is actually a veiled suicide attempt by the already much-hated software giant:
The breaking tech news this year has been the pervasive spread of “AI” (or rather, statistical modeling based on hidden layer neural networks) into everything. It’s the latest hype bubble now that Cryptocurrencies are no longer the freshest sucker-bait in town, and the media (who these days are mostly stenographers recycling press releases) are screaming at every business in tech to add AI to their product.
Well, Apple and Intel and Microsoft were already in there, but evidently they weren’t in there enough, so now we’re into the silly season with Microsoft’s announcement of CoPilot plus Recall, the product nobody wanted.
CoPilot+ is Microsoft’s LLM-based add-on for Windows, sort of like 2000’s Clippy the Talking Paperclip only with added hallucinations. Clippy was rule-based: a huge bundle of IF … THEN statements hooked together like a 1980s Expert System to help users accomplish what Microsoft believed to be common tasks, but which turned out to be irritatingly unlike anything actual humans wanted to accomplish. Because CoPilot+ is purportedly trained on what users actually do, it looked plausible to someone in marketing at Microsoft that it could deliver on “help the users get stuff done”. Unfortunately, human beings assume that LLMs are sentient and understand the questions they’re asked, rather than being unthinking statistical models that cough up the highest probability answer-shaped object generated in response to any prompt, regardless of whether it’s a truthful answer or not.
Anyway, CoPilot+ is also a play by Microsoft to sell Windows on ARM. Microsoft don’t want to be entirely dependent on Intel, especially as Intel’s share of the global microprocessor market is rapidly shrinking, so they’ve been trying to boost Windows on ARM to orbital velocity for a decade now. The new CoPilot+ branded PCs going on sale later this month are marketed as being suitable for AI (spot the sucker-bait there?) and have powerful new ARM processors from Qualcomm, which are pitched as “Macbook Air killers”, largely because they’re playing catch-up with Apple’s M-series ARM-based processors in terms of processing power per watt and having an on-device coprocessor optimized for training neural networks.
Having built the hardware and the operating system Microsoft faces the inevitable question, why would a customer want this stuff? And being Microsoft, they took the first answer that bubbled up from their in-company echo chamber and pitched it at the market as a forced update to Windows 11. And the internet promptly exploded.
First, a word about Apple. Apple have been quietly adding AI features to macOS and iOS for the past several years. In fact, they got serious about AI in 2015, and every Apple Silicon processor they’ve released since 2016 has had a neural engine (an AI coprocessor) on board. Now that the older phones and laptops are hitting end of life, the most recent operating system releases are rolling out AI-based features. For example, there’s on-device OCR for text embedded in any image. There’s a language translation service for the OCR output, too. I can point my phone at a brochure or menu in a language I can’t read, activate the camera, and immediately read a surprisingly good translation: this is an actually useful feature of AI. (The ability to tag all the photos in my Photos library with the names of people present in them, and to search for people, is likewise moderately useful: the jury is still out on the pet recognition, though.) So the Apple roll-out of AI has so far been uneventful and unobjectionable, with a focus on identifying things people want to do and making them easier.
Microsoft Recall is not that.
Comments Off on Microsoft’s latest ploy to be the most hated tech company