That may explain the extraordinary amount of sucking up to Canada in this movie [Bowling for Columbine], which, while gratifying to insecure Canucks and self-loathing Americans, may be of less interest to third parties. Moore’s thesis, such as it is, is that America’s murder rate is the consequence not just of the country’s love of guns but of deeper currents of paranoia and fear in the American psyche. To that end, he crosses the Michigan border into Ontario, where one Canadian after another tells him that they don’t lock their doors. The level of guns per capita in Canada is similar to America but the murder rate is much, much lower. Ergo, it must be because Americans are living in fear while Canadians are much more socially progressive.
Whatever, dude. Unlike Moore, I have homes on both sides of the border and it’s the Quebec one I keep locked. By the time you read this, I’ll be in New York, but my home in New Hampshire will be unlocked, and so will my car at the airport, the key in the ignition, so I’ll know where to find it. By contrast, in Quebec it’s illegal to leave your car unlocked, even if you stop for a pee on an ice floe up by Hudson’s Bay. Pace Moore, Canada has vastly lower rates of handgun ownership. Long-gun ownership is much closer, but, statistically, Canadians are slightly more murderous than Americans in this sphere: in the US, there are 1.7 homicides per 100,000 long guns; in Canada, it’s 1.9. So European visitors to North America should be aware they’re more likely to be killed by a homicidal Canadian rifleman than an American one.
On the overall murder rate, if Moore’s interested in “cultural differences”, it seems odd that he should avoid the most obvious one. Alberta Report‘s Colby Cosh, a braver man than I, points out that black Americans are 13 per cent of the US population but commit over half the murders. Once you factor those out, non-black Americans murder at about the same rate as Canadians.
Mark Steyn, “Bowling for Columbine”, Steyn Online, 2002-11-30.
July 20, 2024
QotD: Comparing gun crime in Canada and the United States
July 4, 2024
Argentina’s inflation rate
As you may have noticed, my interest in Argentinian affairs increased a lot with the election of Javier Milei as President. His first six months in office, while turbulent, do seem to have the economic indicators moving in the right direction for ordinary Argentines:
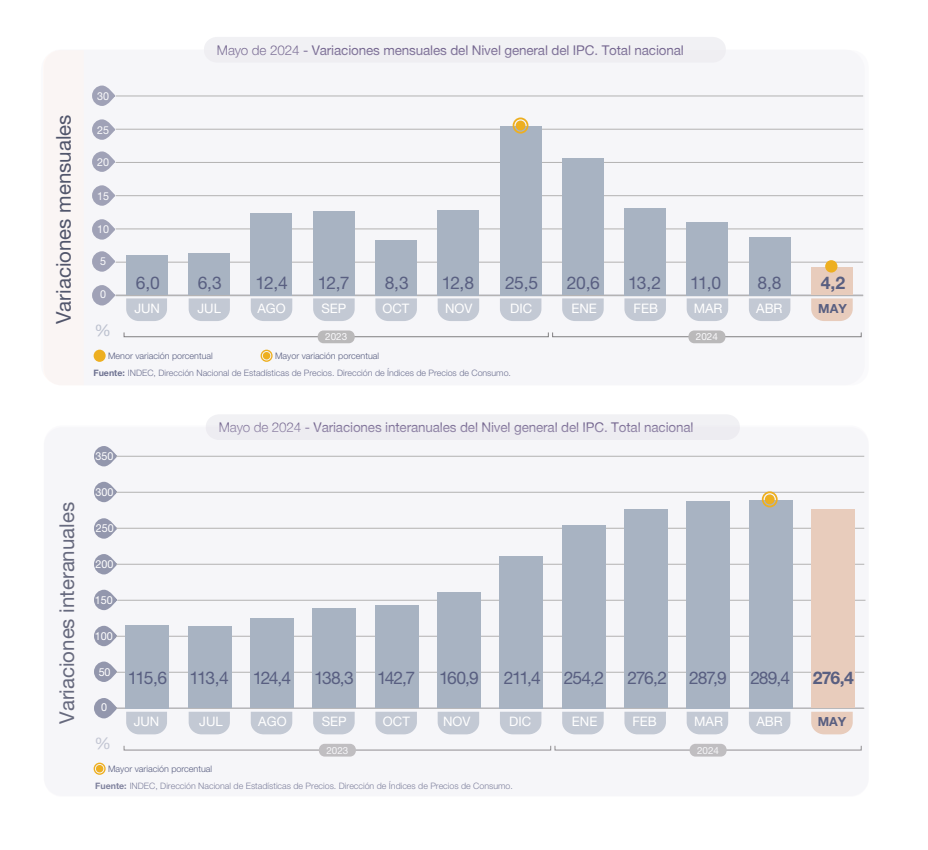
Argentina’s inflation rate has recently dropped to its lowest point since January 2022, registering a monthly increase of 4.2 percent in May according to the National Institute of Statistics and Census (INDEC). Although annual inflation has slowed for the first time since mid-2023, it still stands at 276.4 percent, one of the highest rates globally.
When Javier Milei assumed the presidency in December 2023, monthly inflation had skyrocketed to an unprecedented 25.5 percent. Within five months, Milei’s administration managed to reduce this figure by more than 20 percentage points. Despite the persistently high annual inflation rate, the trend indicates potential stabilization of the Argentine economy.
Javier Milei’s reforms have been described as aggressive. In his inaugural speech, he emphasized the need to clean up the economy before implementing his promises to dollarize and close the central bank.
To achieve a zero deficit, Milei enacted a 35 percent reduction in public spending. He achieved this by closing half of the ministries and secretariats, suspending public works for a year, reducing subsidies for energy and transportation, canceling government advertising, and maintaining the 2023 budget for 2024 despite an inflation rate of 300 percent. Essentially, the government drastically cut its expenditures.
These measures, although unpopular, yielded results. Milei’s government not only avoided a deficit, but achieved a surplus, and most importantly, inflation began to decline.
Following the inflation story in Argentina recently brought to mind Henry Hazlitt’s famous 1978 article “Inflation in One Page“. As the title suggests, Hazlitt summarizes the causes and remedies of inflation in a brief and simple explanation. He argued that inflation is a consequence of government monetary policies, specifically excessive money printing due to unbalanced budgets caused by extravagant government spending.
June 14, 2024
Britain’s anti-gay hate crime epidemic
Andrew Doyle suggests you take the recent reports of burgeoning hate crime in Britain with a fair bit of salt, because the hate crime statistics are far from trustworthy:

When things like this can be reported as “hate crimes”, and the definition depends on the reporter’s assumption of hateful intent, you’re going to see a lot more “hate crimes”.
We all know by now that the Metro is an activist publication masquerading as a newspaper. And so we ought to approach with some caution its article this week claiming that the UK has seen a surge in hate crime against gay people. There’s even a handy rainbow-coloured map which pinpoints the most homophobic locations in the country. Thankfully St Ives isn’t on the list, so I won’t have to cancel my holiday.
What are we to make of the article’s claim that there has been a 462% increase in homophobic hate crime and a 1,426% increase in transphobic hate crime since 2012? The source for these remarkable figures is the House of Commons Hate Crime Statistics report. If true, it would seem to confirm activists’ claims that we are living in an anti-LGBTQIA+ hellhole.
The truth is not so melodramatic. The supposed escalation of hate crimes in the UK can be accounted for by the way in which they are now recorded. Police actively trawl for complaints, inviting citizens to report offensive comments or any action – criminal or otherwise – that the “victim” perceives to have been motivated by prejudice. No evidence of “hate” is required for it to be recorded as such, other than the assumption of the complainant. With such methodology in place, it is inevitable that the statistics will rise.
And perhaps that’s the whole point. The police in the UK are just one of the many major institutions that has been captured by intersectional ideology. Police are regularly seen dancing at Pride parades, driving rainbow-coloured cars, and harassing gender-critical women for wrongthink. In February 2021 in Merseyside – a county that tops the Metro‘s list of homophobic hate spots – police were photographed next to a digital advertisement which read “Being offensive is an offence”. This belief-system can only be sustained by the narrative of widespread hate, and so we should not be surprised to see that police practice has been modified to ensure this outcome.
In fact, the College of Policing had made it clear that a fall in hate crime statistics would not be acceptable. Its operational guidance says that “targets that see success as reducing hate crime are not appropriate”. And by the Home Office’s own admission, “increases in police-recorded hate crime in recent years have been driven by improvements in crime recording and a better identification of what constitutes a hate crime”. In other words, there is no hate crime epidemic at all. It’s simply that the definitions have expanded.
Rather than rely on the Home Office statistics, we would be better turning to a source that hasn’t been corrupted by ideology. The Crime Survey for England and Wales hasn’t adopted the new police methods of recording, and shows that hate crime has been consistently dropping. Between 2008 and 2020, the number of hate crimes fell by 38%, and all the while records of hate crime kept by the police kept on rising. The disparity between the reality and the narrative couldn’t be more stark.
June 7, 2024
Since 2015, the Trudeau Liberals have done a fantastic job of suppressing the Canadian economy
If Canadians elected Justin Trudeau and the Liberal Party to make major changes from what had gone on under Stephen Harper’s Conservatives, then they got their wish in so many different ways, but especially economically:
Reports of Canada’s dismal economic outcomes seem never to end. Why should they? For years Canadians have had the same federal government delivering the same deleterious economic policies and the same expansion in regulatory initiatives and spending that have invariably depressed economies and reduced standards of living whenever and wherever they are imposed. Therefore, until the federal government or its policies change, we should not expect the miserable results to materially improve.
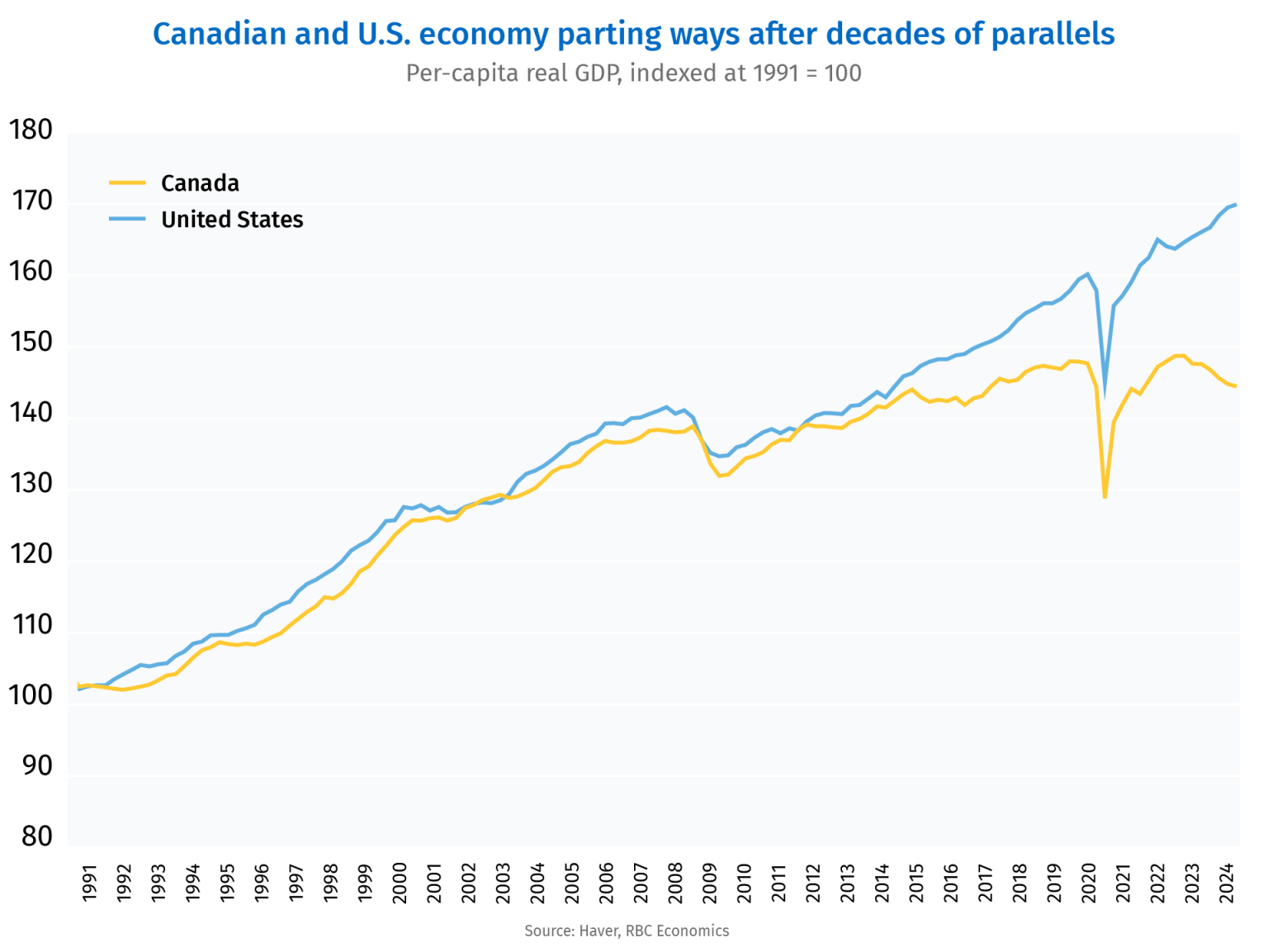
The latest negative report is the release of Canada’s 2024-Q1 GDP numbers on Friday, which again showed sluggish growth relative to population, resulting in yet another quarterly decline in real GDP per capita. Relative to 2015-Q3, the last full quarter before the Trudeau government took office, cumulative real GDP per capita is up only about 0.7 per cent. A recent RBC Economics analysis showed from around 1991 to 2015, cumulative real GDP per capita growth in Canada approximately tracked with the U.S., but not since Justin Trudeau took office. Compared to 0.7 per cent growth in Canada from 2015-Q3 to 2024-Q1, real GDP per capita is up 15.7 per cent in the U.S. in the same time period.
Where the 0.7 per cent comes from matters, too. In real per capita terms, some components of GDP — mainly government — expanded while others contracted. Alarmingly, business investment, which drives productivity and standards of living, is down 13.9 per cent. This includes real per capita reductions of 15.2 per cent in residential structures, 18.4 per cent in machinery and equipment, and 19.3 per cent in non-residential structures, with an increase in intellectual property investment not nearly enough to offset the reductions in other categories.
To understand why business investment and economic performance in Canada are so poor under the Trudeau government, let us consider the following representative example of its economic strategy.
The government believes many families struggle with the cost of caring for young children, which is a legitimate concern. A reasonable solution, which the Harper government implemented in 2006, is to send money to families with young children and let parents buy for their children what they need. After the Liberals expanded that program, they could have left it at that, but what have they done instead? The government initiated a national takeover of child care, effectively expropriating child care entrepreneurs’ businesses by flooding their sector with public money and then controlling private companies’ revenues and operations. The result is child care entrepreneurs’ investments have been wiped out or severely reduced, control of their business operations have been wrestled away by government, and they are unable to properly serve their customers (the families), as evidenced by the drastic reduction in parental options and widespread shortages.
May 22, 2024
If you re-define it carefully, you can make any statistical measure look hopeful
In his Substack, Tim Worstall jokingly called this piece “Larry Summers Explains Why Americans Hate Joe Biden”:
As a good Democrat of course Larry Summers would never put things in quite that headline way. But the implication of this latest paper with others is to explain why Americans really aren’t as happy as they should be given the economic numbers. The answer being that the economic numbers we all look at to explain how happy folk are aren’t the right economic numbers to explain how happy people are.
We can also make — possibly rightly, possibly wrongly, this might be me projecting more than is merited — a further claim. That Americans simply aren’t as rich as those standard economic numbers suggest either. Which would also neatly explain the general down in the dumps attitude toward the economy.
So, the new paper:
Unemployment is low and inflation is falling, but consumer sentiment remains depressed. This has confounded economists, who historically rely on these two variables to gauge how consumers feel about the economy. We propose that borrowing costs, which have grown at rates they had not reached in decades, do much to explain this gap. The cost of money is not currently included in traditional price indexes, indicating a disconnect between the measures favored by economists and the effective costs borne by consumers. We show that the lows in US consumer sentiment that cannot be explained by unemployment and official inflation are strongly correlated with borrowing costs and consumer credit supply. Concerns over borrowing costs, which have historically tracked the cost of money, are at their highest levels since the Volcker-era. We then develop alternative measures of inflation that include borrowing costs and can account for almost three quarters of the gap in US consumer sentiment in 2023. Global evidence shows that consumer sentiment gaps across countries are also strongly correlated with changes in interest rates. Proposed U.S.-specific factors do not find much supportive evidence abroad.
OK, or as explained by the Telegraph:
In it, the authors made a shocking claim: if inflation was measured in the same way that it was measured during the last bout of price rises in the 1970s, data showed that it peaked at 18pc in November 2022. This is far higher than the 9.1pc peak inflation shown by the official data.
The reason for this discrepancy is that, since the 1970s, economists have removed the cost of borrowing from the Consumer Price Index (CPI). The motivations here were not nefarious. The reasoning of the statisticians had something to it.
And, OK, if inflation peaked at 18%, not 9%, then that would explain why folk are pissed. Sure it would.
[…]
OK. But that means that if inflation was higher than we’ve been using then the deflation of nominal to real GDP is also wrong. Just that one year of 9% recorded but 18% by this new measure is damn near a 10% difference. That’s how much we’re over-estimating real GDP by right now. Add in a couple of years of lower levels of that and being 20% out wouldn’t surprise.
Which would mean that — if this were true and I might be overegging it — Americans are in fact 20% poorer than the Biden Admin keeps saying they are. And yes, that would piss the voters off, wouldn’t it?
Gaslighting has been a staple of the legacy media for quite some time now, going into high gear during the 2016 US Presidential elections and then into overdrive during the pandemic. They probably don’t even realize they’re doing it any more, because it feels “normal” to them. Yet they wonder why their popularity and public trust in their pronouncements continues to drop.
April 23, 2024
Debating the economic impact of the Raj on India
At The Daily Sceptic, Nigel Biggar looks at a few books making or refuting the narrative on how much or how little British rule in India extracted or contributed to the economic life of the subcontinent:

Beyond slave-trading and slavery, what were the economic effects of British imperial dominance? Can they be reduced to Britain’s leeching wealth from exploited subject peoples?
For over a century, that is what Indian nationalists have claimed. It is also what the politician Shashi Tharoor claims in his 2016 book, Inglorious Empire: What the British Did to India. Against him, however, the Bengali-born, LSE-based economic historian Tirthankar Roy has declared of the nationalist critique that “generations of historians … have shown that it is not [true]”. Pace Tharoor, the statistic that India produced 25 per cent of world output in 1800 and 2–4 per cent in 1900 does not prove that India was once rich and became poor: “[i]t only tells that industrial productivity in the West increased four to six times during this period … The proposition that the Empire was at bottom a mechanism of surplus appropriation and transfer has not fared well in global history”.
On the contrary, the British Empire’s commitment to free trade gave Indian entrepreneurs new opportunities to grow. Some of them visited England in the late 19th Century, observed the workings of manufacturing industry, imported machinery and expertise to India, built factories employing Indians, and then outcompeted Manchester. This is exactly how the Tata Iron and Steel Company began in Bombay – the same company that now owns what remains of the British steel industry.
What is more, colonial governments often protected native producers against British business, in order to moderate economic and social disruption, partly because they genuinely cared for the welfare of native people and partly because they didn’t want to have to manage the political unrest that foreign commercial intrusion could excite. Famously, in 1910-11 colonial officials barred Lever Brothers from acquiring concessions in Nigeria on which to establish palm-oil processing mills with widespread hinterlands, since Africans were already producing for the world markets and generating tax revenue and because the alienation of large areas of land risked provoking native opposition.
Further still, the British were the leading exporters of capital from the mid-19th Century to at least 1929. Between 1876 and 1914, Britain invested over a third of its overseas capital in the Empire, over 19% of it in India. Of course, British investors often made a profit out of this. That’s the thing about investment: you tend to want to grow your money, not waste it. But if the British gained, so did colonial peoples. Take railways. By 1947, British India had 45,000 miles of railway track, most of it constructed with private capital, whereas five years later un-colonised China still had less than 18,000 miles. For sure, the railways served military purposes. But they also served commercial and economic ones: one estimate reckons that when the railway network reached the average district, real agricultural income rose by about 16%. And it served the welfare purpose of efficient famine relief, too.
A basic reason why the British sent their capital overseas to the Empire, enabling the growth of businesses and the building of infrastructure, was that colonial states provided sufficient political stability and legal certainty to make the risks of financial ventures worth taking. (Badenoch hints at this in her reference to the economic effects of the Glorious Revolution of 1688.) That explains why Australia’s economic growth compares so favourably with that of many Latin American countries, and why, between the 1860s and 1890s, Australia was the richest country on earth.
In sum, the considered judgement of the Swiss historian Rudolf von Albertini, whose work – according to the world’s “leading imperial economic historian”, David Fieldhouse – was based “on exhaustive examination of the literature on most parts of the colonial world to 1940”, was simply this: “colonial economics cannot be understood through concepts such as plunder economics and exploitation”.
QotD: Who cares about you?
Alchian, donning a mischievous smile asked, “Williams, have you considered a third alternative, namely, that people don’t give a damn about you one way or another?” Initially, I felt a bit insulted, and our conversation didn’t go much further, but that was typical of Alchian — saying something profound, perhaps controversial, without much comment and letting you think it out.
Years later, I gave Alchian’s third alternative considerable thought and concluded that he was right. The most reliable assumption, in terms of the conduct of one’s life, is to assume that people don’t care about you one way or another. It’s an error to generalize that people are friends or enemies, or that people are out to either help you or hurt you. To put it more crudely, as Alchian did, people don’t give a damn about you one way or another.
Walter E. Williams, “Who Cares About You?”, Townhall.com, 2019-10-01.
January 28, 2024
QotD: Never depend on “surveys” for real-world issues
The respondent pool is, overwhelmingly, college kids taking them for class credit. Knowing what we know about Basic College Girls, who again are the majority of all college kids, is it any surprise that the results just happen to confirm the conclusions the slightly older, but no less Basic, Grad Student Girls were looking for? Throw in the design problem — questions about as subtle as “Do you think all races should be treated equally, or are you a monster?” — and you’ve got scientific proof that Liberals are good people and Conservatives suck.
Severian, “Is vs. Ought II: Moral Foundations Theory”, Rotten Chestnuts, 2021-04-20.
January 23, 2024
QotD: Shakespeare was apparently a terrible writer, according to Bayesian analysis
First there is the dull, seemingly steady, respectable type, instantiated by Bernie Madoff, who had just the kind of personal gravitas that inspired confidence in the cautious. “Yes,” the cautious type thought as he gazed into Madoff’s calm and wise face, “he is just the type to whom I can safely entrust my money. He knows, if anyone knows, how to make money fruitful and multiply.”‘ His very dullness obscured from the cautious man the fact that he, the cautious man, was as motivated by greed and lust for painless enrichment as the most reckless gambler; and no man wants to think that he is motivated by greed. That is a vice that motivates others, not oneself.
Second there is the flamboyant genius type. For more adventurous investors in search of quick returns, a man like SBF is just the one to follow. His refusal to comply with elementary social conventions, even his wild hair, stood guarantor of his genius. Those who followed SBF as the children followed the pied piper deluded themselves by the following false syllogism:
Geniuses are unconventional.
SBF is unconventional.
Therefore, SBF is a genius.(Actually, even his unconventionality was conventional. Convention is that from which no man can ever fully escape.)
The nature of SBF’s “genius” has come to light in his thoughts of Shakespeare, against whose genius he applies statistical reasoning:
I could go on and on about the failings of Shakespeare … but really I shouldn’t need to: the Bayesian priors are pretty damning. About half the people born since 1600 have been born in the past 100 years, but it gets much worse than that. When Shakespeare wrote, almost all Europeans were busy farming and very few people attended university; few people were even literate — probably as low as ten million people. By contrast there are now upwards of a billion literate people in the Western sphere. What are the odds that the greatest writer would have been born in 1564? The Bayesian priors aren’t very favourable.
One could have a great deal of fun with this argument, for example by proving statistically that Isaac Newton was not one of the greatest physicists who ever lived, and indeed could never really even have existed, because the number of people in his time who could do simple arithmetic was so exiguous. How could he, then, together with Leibniz (another impossibility), have invented the calculus?
By contrast, we could also prove that we are living through a golden age of literature (as of every art) because there are now so many people who know how to write. Of course, our painting must be best because, comparatively speaking, our materials are so cheap and within the range of most people, all of whom have the time to take up painting. Think of how poor Spain was when Velasquez was painting! In Vermeer’s day they didn’t even have flush toilets! How, then, could his paintings be beautiful? Basquiat’s paintings must be much better because now we have electric light.
How could Dickens have been so funny when the infant mortality rate was so high and the life expectancy so low? Therefore, he was not funny. As for Mozart, he didn’t even have an electronic amplifier to his name, so how could his music have been any good? He hadn’t even heard of rap.
One swallow doesn’t make a summer, of course, or one vulture a flock, but one cannot help but remark that SBF was not some poor child who managed, by hook or by crook, to crawl out of a noisome slum, but the child of two professors at Stanford University (admittedly of law) who was himself expensively educated and who was, by the standards of 99.999 percent of all previously existing humanity (to use an SBFian type of statistic), extremely privileged. He was of the elite. His immortal thoughts on Shakespeare would not have been possible without his education, for they certainly would not have occurred to — shall we say — an illiterate illegal immigrant from El Salvador or Honduras.
No, it requires many years of training to come up with arguments such as his. And this in turn raises the question of what is going on in schools and universities (if, that is, SBF is not completely sui generis) that their alumni end up by saying things that make the pronouncements of Azande witch doctors look like those of the latest science. Perhaps — and let us hope that — SBF is not typical of his breed.
Theodore Dalrymple, “The Literary Financier”, New English Review, 2023-10-21.
January 17, 2024
QotD: Did Hari Seldon live in vain?
Such complex causation defies general laws (even before we get into the fact that humans also observe history, which creates even more complexity) with such tremendous import from such unlikely events in an experiment which can only be run once without a control.
The other problem is evidence. Attempting to actually diagnose and model societies like this demands a lot of the data and not merely that you need a lot of it. You need consistent data which projects very far back in history which is accurate and fairly complete, so that it can be effectively compared. Trying, for instance, to compare ancient population estimates, which often have error bars of 100% or more, with modern, far more precise population estimates is bound to cause some real problems in teasing out clear correlations in data. The assumptions you make in tuning those ancient population figures can and will swallow any conclusions you might draw from the comparison with modern figures beyond the fairly obvious (there are more people now). But even the strongest administrative states now have tremendous difficulty getting good data on their own lower classes! Much of the “data” we think we have are themselves statistical estimates. The situation even in the very recent past is much worse and only degrades from there as one goes further back!
By way of example, I was stunned that Turchin figures he can identify “elite overproduction” and quantify wealth concentration into the deep past, including into the ancient world (Romans, late Bronze Age, etc). I study the Romans; their empire is only 2,000 years ago and moreover probably the single best-attested ancient society apart from perhaps Egypt or China (and even then I think Rome comes out quite solidly ahead). And even in that context, our estimates for the population of Roman Italy range from c. 5m to three to four times that much. Estimates for the size of the Roman budget under Augustus or Tiberius (again, by far the best attested period we have) range wildly (though within an order of magnitude, perhaps around 800 million sestertii). Even establishing a baseline for this society with the kind of precision that might let you measure important but modest increases in the size of the elite is functionally impossible with such limited data.
When it comes to elites, we have at best only one historical datapoint for the size of the top Roman census class (the ordo equester) and it’s in 225 BC, but as reported by Polybius in the 140s and also he may have done the math wrong and it also isn’t clear if he’s actually captured the size of the census class! We know in the imperial period what the minimum wealth requirement to be in the Senate was, but we don’t know what the average wealth of a senator was (we tend to hopefully assume that Pliny the Younger is broadly typically, but he might not have been!), nor do we know the size of the senatorial class itself (formed as a distinct class only in the empire), nor do we know how many households there were of senatorial wealth but which didn’t serve in the Senate because their members opted not to run for public office. One can, of course, make educated guesses for these things (it is often useful and important to do so), but they are estimates founded on guesses supported by suppositions; a castle of sand balanced atop other castles of sand. We can say with some confidence that the Late Roman Republic and the Early Roman Empire saw tremendous concentrations of wealth; can we quantity that with much accuracy? No, not really; we can make very rough estimates, but these are at the mercy of their simplifying assumptions.
And this is, to be clear, the very best attested ancient society and only about 2,000 years old at that. The data situation for other ancient societies can only be worse – unless, unless one begins by assuming elite overproduction is a general feature of complex, wealthy societies and then reads that conclusion backwards into what little data exists. But that isn’t historical research; it is merely elevating confirmation bias to a research methodology.
As noted, I have other nitpicks – particularly the tendency to present very old ideas as new discoveries, like secular cycles (Polybius, late 2nd century BC) or war as the foundation of complex societies (Heraclitus, d. c. 475 BC) without always seeming to appreciate just how old and how frequently recurring the idea is (such that it might, for instance, be the sort of intuitive idea many people might independently come up with, even if it was untrue or that it might be the kind of idea that historians had considered long ago and largely rejected for well established reasons) – but this will, I hope, suffice for a basic explanation of why I find the idea of this approach unsatisfying. This is, to be clear, not a rejection of the role of data or statistics in history, both of which can be tremendously important. Nor is it a rejection of the possible contributions of non-historians (who have important contributions to make), though I would ask that someone wading into the field familiarize themselves with it (perhaps by doing some traditional historical research), before declaring they had revolutionized the field. Rather it is an argument both that these things cannot replace more traditional historical methods and also that their employment, like the employment of any historical method, must come with a very strong dose of epistemic humility.
Psychohistory only works in science fiction where the author, as the god of his universe, can make it work. Today’s psychohistorians have no such power.
Bret Devereaux, “Fireside Friday: October 15, 2021”, A Collection of Unmitigated Pedantry, 2021-10-15.
1. For those confused by the causation, the Mongols are considered the most likely vector for the transmission of gunpowder from China, where it was invented, to Europe. Needless to say, having a single polity spanning the entire Eurasian Steppe at the precise historical moment for this to occur sure seems like a low probability event! In any event, European mastery of gunpowder led directly into European naval dominance in the world’s oceans (its impact on land warfare dominance is much more complex) which in turn led to European dominance at sea. At the same time, the English emphasis on gunnery over boarding actions early in this period (gunpowder again) provided a key advantage which contributed to subsequent British naval dominance among European powers (and also the British navy’s “cult of gunnery” in evidence to the World Wars at least), which in turn allowed for the wide diffusion of English as a business and trade language. In turn, American and British prominence in the post-WWII global order made English the natural language for NATO and thus the ICAO convention that English be used universally for all aircraft communication.
January 10, 2024
The unexpected rise in “Unknown Cause”
Mark Steyn rounds up some interesting details on that long-forgotten-by-the-media pandemic and corresponding heavy-handed government interventions that made things so much worse:

The obvious problem with appeals to authority, at least for anyone more sentient than an earthworm, is that across the western world the last four years have been one giant appeal to authority – and the result of mortgaging the entirety of human existence to the expert class is the rubble all around. Just for starters:
US scientists held secret talks with Covid ‘Batwoman’ amid drive to make coronaviruses more deadly
You don’t say! When would that have been? Oh:
…just before pandemic
Well, there’s a surprise!
A new cache of documents, obtained by Freedom of Information campaigners and seen by The Mail on Sunday, reveal the extent to which the controversial work at the Wuhan Institute of Virology was supported, and often funded, by America.
You got that right. Wuhan is the virological equivalent of a CIA black site in Pakistan: it’s where the Deep State goes to do the stuff it can’t do in suburban Virginia.
So how’s that working out for the planet? Way back in 2022, The Mark Steyn Show reported that “Unknown Cause” was now the leading cause of death in Alberta. According to the somewhat lethargic lads at Statistics Canada, taking eighteen month to catch up with yours truly, that same year it was the fourth leading cause of death across the entire country. “Unknown Cause” is rampaging from Nunavut igloos to the Hamas branch office in Montreal: Between 2019 and 2022, it was up almost five hundred per cent.
Does “Unknown Cause” have an awareness-raising ribbon like Aids or breast cancer? Are there any celebs who’d like to headline a gala fundraiser or do an all-star pop anthem?
Apparently not. Gee, it’s almost as if taking too great an interest in “Unknown Cause” can lead to a bad case of cancer of the career. Nevertheless, the official StatsCan numbers are, to put it at its mildest, odd. By the end of 2022, Canada was one of the most jabbed nations on earth, with a Covid vaccination rate of ninety-one per cent, the highest in the G7, by some distance (UK and US both at eighty per cent).
And yet, if these government numbers are to be believed, something very strange happened. In the most jabbed member of the G7, Covid deaths went up. As The Western Standard‘s Joseph Fournier noticed, while almost nobody else did, Covid deaths per annum across the Deathbed Dominion shot up 25 per cent from the days of curfews, and arrests for playing open-air hockey:
2020 15,890
2021 14,466
2022 19,716
So, in Jabba Jabba Central, more people died of Covid in the most recent annual round-up than at the height of the pandemic. In fact, on those numbers, Canada has yet to reach “the height of the pandemic”. Here’s another striking feature – again, direct from Statistics Canada:
During the first year of the pandemic, older Canadians (65 years of age and older) accounted for 94.1% of COVID-19 deaths, while those aged 45 to 64 years accounted for 5.3%. In 2021, while the number of COVID-19 deaths among individuals aged 65 years and older (82.0%) remained high, the proportion of deaths among those aged 45 to 64 years nearly tripled to 15.5%.
So, in the most vaxxed nation of the G7, middle-aged persons account for three times the proportion of Covid deaths than they did at “the height of the pandemic”.
Like I said: odd.
Canadian life expectancy? Down. Oh, just by four months or so. But that’s three times the size of last year’s drop.
Excess mortality? Indeed: In 2019 the age-standardised death rate was 830.5 per 100,000 people. In 2022 it was 972.5. As I’ve pointed out a gazillion times on telly, that’s the opposite of what’s meant to happen post-pandemic: After the Spanish Flu, the mortality rate fell because people who would otherwise have died in 1924 had already died in 1919. That phenomenon is visible in Eastern Europe, but nowhere in the Dominion of Death.
Last year I mentioned en passant to my friend Naomi Wolf that the Covid vaccines were beginning to remind me of the scandals of her old chum Bill Clinton: one such can do a politician in, but, if you have (as Slick Willy did) a multitude of ’em, who can follow it all? If Pfizer, Moderna and AstraZeneca just caused, say, myocarditis, maybe people would find it easier to focus on. Instead, it causes myocarditis in men and infertility in women and, if you manage to dodge the latter, the mRNA shows up in newborn babies; it brings on Guillain–Barré syndrome and Ramsay Hunt syndrome and lightning-speed turbo-cancers. Alternatively, you could get a dose of the SADS and drop dead on stage or on the footie pitch, or at home watching the telly. It’s a lot to keep track of.
Or maybe, as in Alberta, you just die of … whatever. And nobody cares to find out.
January 5, 2024
QotD: Hong Kong and the “league table” of world economic freedom
The same countries typically appear at the top from year to year, and are separated mostly by microscopic, irrelevant differences. For 2017, whence the data in the new report come, Canada sat in eighth place just a hair above Australia and a hair below the U.K. Ascending to the top, we meet other siblings of the English-speaking world, Ireland and the U.S.; the Swiss Republic stands in its typical fourth; the relatively wild child of the Commonwealth, New Zealand, remains third; and then, in the top two places, you have the twin beacons of radical economic freedom, Singapore and Hong Kong.
Ah, yes, Hong Kong. The Special Administrative Region seems, for now, to have won a short-term victory in its struggle to preserve the conditions of its reunion with mainland China. This has not, ostensively, been a struggle over economic freedom per se, but it is not a coincidence that the rioting ultimately originated in a conflict over bookstores. It is mighty hard to draw a line where “economic” freedom stops and purely personal or civil freedoms begin, and the design of the index reflects this. It has a large basic rule-of-law component, includes mobility rights under the free trade factor, and takes points away for imposing military conscription. (This is surely a tiny tribute to the shade of Milton Friedman, who was one of the originators of the index.)
Even if Hong Kong’s immediate quarrel with China has been resolved for now, it is only a manifestation of what is likely to be a longer game. Clever columnists always like exoticizing talk about how the Chinese think in generations, but when it comes to Hong Kong, the cliché has weight. The 2019 riots, in showing how attached young HKers are to their distinct identity and to the English-speaking world, have revealed a nightmarish, even delegitimizing failure by the Chinese Communists. Mainland influence on Hong Kong education and politics has been used with the intention of prolonging and deepening the spirit of ’97; China, so often deemed the super-country of the future by admiring or fearful intellectuals, has tested the results of this effort in the eyes of the world and been made a laughingstock.
Colby Cosh, “Hong Kong’s still king in economic freedom rankings … for now”, National Post, 2019-09-17.
January 3, 2024
“One of the oddities of trans healthcare is that it masquerades as progressive”
In The Critic, Victoria Smith outlines the history of medical misogyny from Aristotle to modern-day “trans healthcare”:

The neglect of female bodies in medicine has a long history. The male-default bias, writes Caroline Criado Perez in Invisible Women, “goes back at least to the ancient Greeks, who kicked off the trend of seeing the female body as a ‘mutilated male’ body (thanks, Aristotle)”:
The female was the male ‘turned outside in’. Ovaries were female testicles (they were not given their own name until the seventeenth century) and the uterus was the female scrotum. […] The male body was an ideal women failed to live up to.
As Criado Perez notes, this bias lives on in male-centric medical research and undifferentiated treatment recommendations. “Women are dying,” she notes, “as a result of the gender data gap.” The belief that there is nothing specifically different about female people — cut a bit here, add a bit there, and we’re the same as men — has led to our symptoms being ignored and our pain dismissed.
Over the past few years, there have been a number of books — Elinor Cleghorn’s Unwell Women, Cat Bohannon’s Eve, Leah Hazzard’s Womb, to name a few — which have aimed to correct the imbalance. This is important both to save lives and ease suffering, and because, on a very basic level, it is insulting for half the human race to have our bodies treated as lesser, imperfect versions of a male ideal. We are more than that. We exist in our own right.
There are many in medicine, however, who still seem to think that Aristotle was right. Last week, for instance, the World Health Organisation announced it would be developing new guidelines into “the health of trans and gender diverse people”. While this might sound positive, as Eliza Mondegreen notes, many of those leading the development group hold highly regressive views about sex, gender and bodies. It is only possible to believe that a person could change sex if you have not given much consideration to the “second” sex at all.
One of the oddities of trans healthcare is that it masquerades as progressive despite having evolved from — and continuing to rely on — an understanding of sex difference which is regressive, male-centric and superficial. Because no one wants to admit it, this has led to a plethora of articles along the lines of “Here’s Why Human Sex Is Not Binary” and “Sex Redefined: The Idea of 2 Sexes Is Overly Simplistic“. While these claim to be adding extra detail and nuance to our understanding, what they do in practice is revert back to privileging the male default. Sex is all so varied, all so different, they tell us, we might as well not bother setting any standards for what counts as “femaleness”. We’re all just human, aren’t we? Only some bodies have tended to be considered more human than others. Rebranding “the male default” “the sex spectrum” is a sneaky way of insisting, once again, that female people are nothing more than males with a few minor tweaks.
This is the new medical misogyny, built on the back of the old version. Unfortunately, because it positions itself as anti-conservative and even pro-feminist, many writers of texts that address the old version feel obliged to go along with the new. It’s not difficult to see why. Who wants their work to be undermined by bad faith accusations of transphobia? Isn’t it easier just to say “it’s clear that trans women are women” — as Bohannon has done — on the basis that at least this will enable you to challenge the centring of male bodies elsewhere?
December 9, 2023
All those (officially unexplained) “excess” mortalities
Mark Steyn discusses European and Antipodean statistical reports that echo what Maxime Bernier was talking about the other day on the as-yet officially unexplained huge rise in “excess mortality” since the Wuhan Coronavirus pandemic:

We are now three years into the administration of the Covid vaccines, and we have many startling statistical anomalies, including the most basic one of all: a huge mound of extra corpses. Per the EU’s official statistics agency:
Among the eighteen EU Member States that recorded excess deaths, the highest rates were in Cyprus (13.9%), Finland (13.4%), the Netherlands (12.7%) and Ireland (12.5%).
Those percentages are sufficiently high that in the Netherlands, formerly one of the healthiest nations on earth, they’re reducing life expectancy. The ongoing excess deaths are at odds with the normal post-pandemic pattern, such as the Spanish Flu a century ago. The intro to this new scientific paper sets out what’s meant to be happening:
Our approach takes into account age and gender, but also under-mortality that you would expect after a period of excess mortality.
“Under-mortality” occurs because, if the Spanish Flu killed you prematurely in 1920, you weren’t around to die when you otherwise would have done in 1924. Hence, excess mortality is followed by under-mortality. So:
If this under-mortality does not seem to be happening, it is actually hidden excess mortality.
That’s an important point. What Eurostat identifies as an excess mortality rate in Ireland of 12.5 per cent is, as a practical matter, actually higher – because it should be measured against not the pre-Covid baseline but the under-mortality one would have expected four years on. So persistent excess mortality is deeply weird, and, unlike those killed by the virus (where the median age of death by Covid is above most developed nations’ life expectancy), the extra deaths, as we have discussed on The Mark Steyn Show, are skewed towards the young and middle-aged:
We note that excess mortality in the Netherlands remains consistently high during 2020-2022 and has shifted from high to low age and towards men.
In other words, it’s not a general trend of excess deaths, but something more particular. Which, in a normal environment, would suggest something particular is causing it. Aside from excess deaths in “low age”, we also have excess deaths at no age – the babies who aren’t being born. The western world’s jabbed and re-jabbed citizenry has seen a catastrophic slump in newborns. Scandinavia:
The whole region reported sharp declines in fertility rates in 2022. Finland had the lowest fertility rate of all Nordic countries, 1.32 children. This is also the lowest Finnish rate since 1776 when monitoring of fertility rates first started.
Incidentally, that Finnish rate – of 1.3 children per woman – is what demographers call “lowest-low fertility”, from which no society has ever recovered.
Fortunately for officialdom, there was enough Covid circulating in Finland, Ireland, the Netherlands, etc that the ever higher mountain of corpses can be shrugged off as most likely “Long Covid” or maybe, if necessary, “Extra-Long Covid”. In the Antipodes, they can’t get away with that. Australia and New Zealand enacted some of the most draconian public-health measures on the planet, and in effect quarantined their entire nations. As a result, pre-Omicron they had all but negligible accounts of Covid. But they obediently submitted themselves to the mass vaccination regime. And, whaddaya know, they too have extraordinary rates of excess death.
Clare Craig, a favourite guest of The Mark Steyn Show, has published a detailed analysis of the post-vaccination years Down Under. It makes for sober reading.
In 2021, for example, they had officially 1,224 deaths from Covid.
But also in 2021 – the first full year of the vaccines – they had 876 excess deaths from ischaemic heart disease alone. Plus another 583 excess deaths from other cardiac diseases.
Death by ischaemic heart disease had been in decline in Australia in the pre-vaccine years, but, having shot up in 2021, it went up even further in 2022. (Same trend with strokes.) So, having shut down the country for those 1,224 Covid deaths, you would think the public health bureaucracy might show a smidgeonette of interest in those 1,359 excess cardiac deaths.
But apparently not.
Now, across the Tasman Sea, we have a Kiwi whistleblower, Barry Young, who has released an avalanche of data with some quite disturbing takeaways that I referenced on Wednesday’s Clubland Q&A. I was careful to qualify my remarks with a lot of “ifs”, but our friend Norman Fenton, Professor of Risk Information Management at Queen Mary University, has taken a look and The Conservative Woman has published his findings. I see that on the Internet the kneejerk reaction was that Mr Young had simply leaked a lot of vaccination stuff from the old folks’ homes where the Covid centenarians would have died anyway. So it’s a biased sample.
In reality, it does not appear to be a “sample” at all:
[Steve Kirsch] says that there are widespread misunderstandings about the data and it is not biased. For a start he says that the dataset is the complete set of ‘pay-per-dose’ vaccination records and therefore there is no biased sampling at all. He says:
“The people within the group is representative of the total population. There are 2.2 million people in the group, and there are 4 million records. Each of those records is a Vaccination Record.”
2.2 million is over forty per cent of the population of New Zealand. That’s some “sample”. Nevertheless, Professor Fenton is being scrupulously cautious:
Even accounting for inevitable “survivor bias” (the more jabs a person gets, the quicker they are likely to die after their last jab) there was some evidence of increased risk the more doses a person gets. Moreover, given Steve’s comments about the datatset being the complete set of “pay-per-dose” vaccination records, this conclusion seems robust even if there were a biased proportion of vaccinee deaths in the dataset. Also (as per my above quote in Steve’s presentation) I felt that the data provided further support for the hypothesis that the vaccine was increasing the mortality rate in the older population (something which we had already concluded based on the most recent ONS data).
It’s interesting that such questions never come up at Britain’s official “Covid inquiry” which is increasingly risible in its palpable determination to find that the only mistake that was made was not to lock down harder and faster.
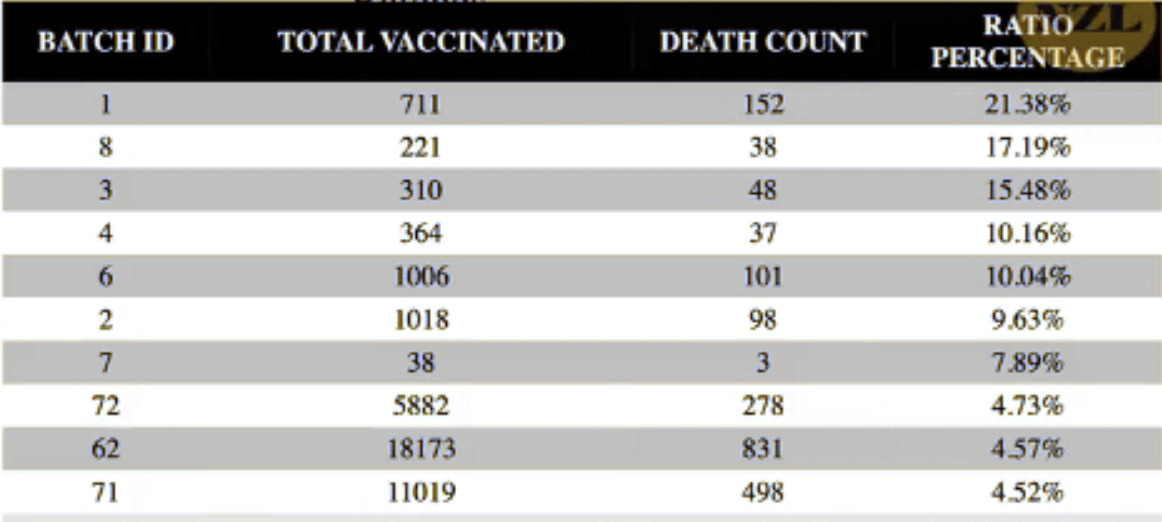
The other takeaway mentioned by Professor Fenton is the fatality rate of individual batches. Take a look at this handy graph:
I suppose it would be possible to argue that all 711 jabs of Batch #1 were administered to residents of the Shady Acres Retirement Home for Centenarians with Stage Four Ebola. But it’s difficult to make the same case with Batch #62 which went into the arms of 18,173 New Zealanders and killed 831 of them. Which, all by itself, is two hundred times the country’s official death toll from the vaccines. Which is to say, according to His Majesty’s Government in Wellington, precisely four Kiwis are dead of the vax.
December 7, 2023
Burying the lede … and the victims
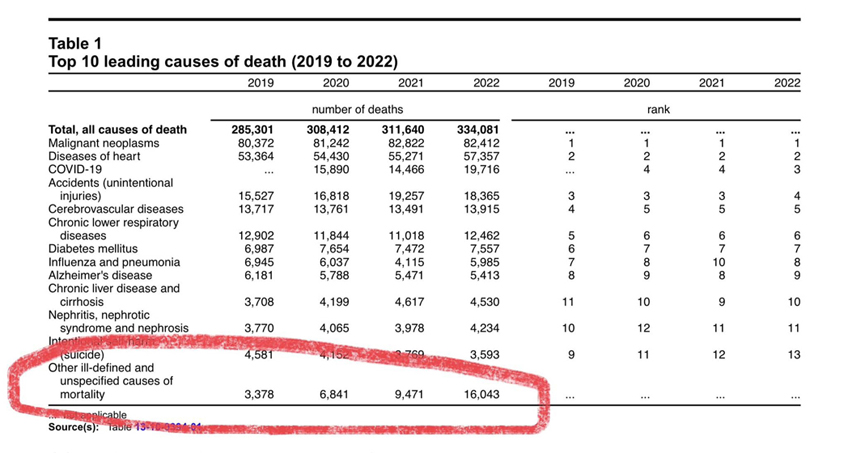
Maxime “Mad Max” Bernier sent out a fundraising letter to PPC supporters that included some disturbing new data from Statistics Canada:
![]()
As usual, the biggest news in Canada is being ignored by all of our crooked establishment politicians and the dishonest corporate media.
Last week Statistics Canada released a report on deaths in Canada (causes of death, overall life expectancy, etc), which include the latest data from 2022.
I’m not a doctor, a scientist, or even a statistician, but when I saw the table below, a few things jumped out at me.
First, deaths related to covid-19 (check the fourth line) were at an all-time high in 2022!
Can you believe that? There were more covid deaths in 2022 than the two years before.
And yet that same year saw the end of mask mandates, vaccine passports, and most covid measures.
For two years the elites blasted us with propaganda and warped our society around this mild illness, but when deaths were rising, they were silent. Bizarre!
To be clear, I am not advocating for any of these unnecessary draconian restrictions to return, I am just demanding some honesty and consistency from our morally corrupt politicians, public health officials, and media!
It has never been so obvious that covid restrictions were not scientific, they were just about politics and control.
But the most disturbing part is what I have circled at the bottom of the table. Deaths with “ill-defined or unspecified causes” have been steadily increasing since 2020.
These deaths have almost TRIPLED since 2020 from 6,841 to 16,043 in 2022.
What could be causing this? What happened in 2021 that could have caused this explosion of unexplained deaths over the last 2 years?
An experimental pharmaceutical product was rushed to market and forced on Canadian society, is what happened.
They told us it was “safe and effective” but over the last few years we have learned more and more about how that covid shot was neither.
Now more and more Canadians are dying from causes very likely related to the covid shot.
And where is the accountability?!
There is no admission of any possible error on the part of the government. On the contrary, it’s still encouraging everyone to get boosters!
There are no demands for an inquiry by the opposition parties to investigate the potential risks associated with the covid jab.
There are no investigative journalists trying to get to the bottom of one of the biggest medical scandals in Canadian history.
No! They’re just trying to sweep it under the rug and move on!
We can’t wait for the political establishment to hold itself to account. We saw throughout the covid years that the government, the opposition, and the media will all work together to protect themselves and each other.
And we can’t let them get away with it!