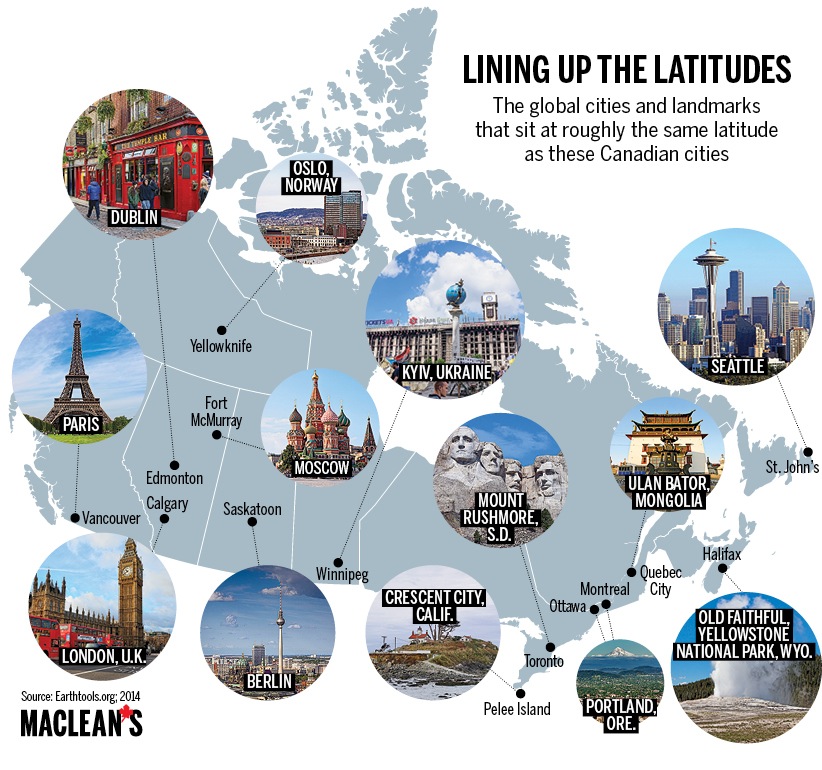
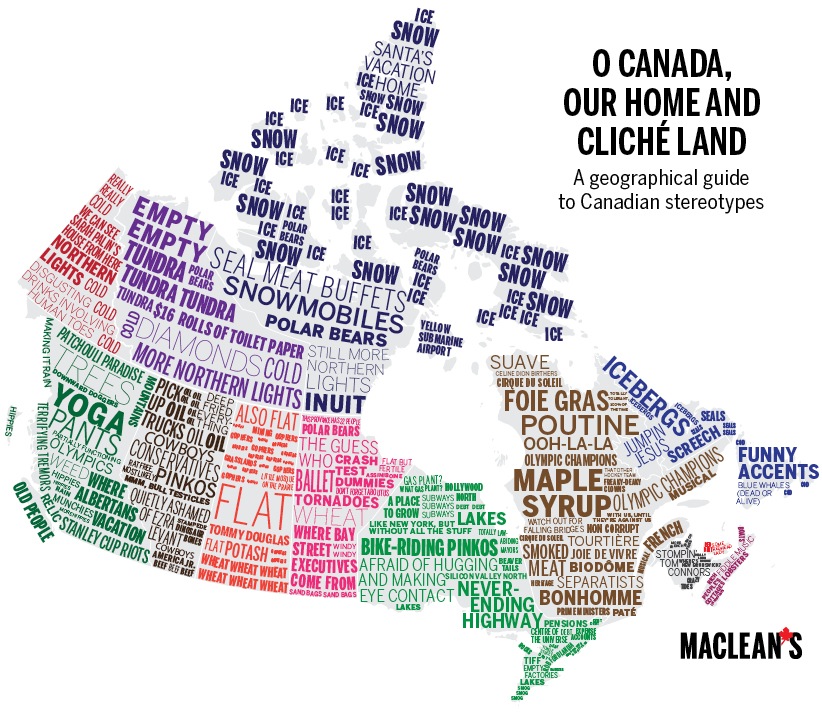
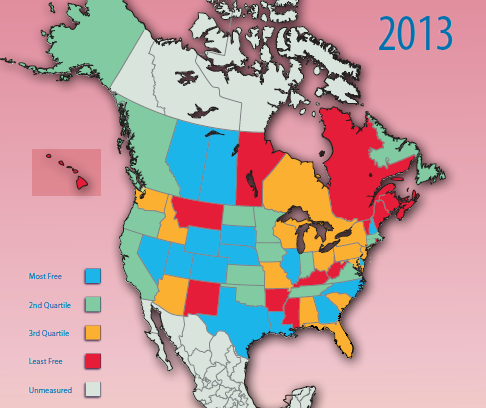
Hmm. Today seems to be health news day. In the Wall Street Journal, Nina Teicholz looks at the dubious science behind the saturated fat demonization we’ve all seen in so many health stories:
“Saturated fat does not cause heart disease” — or so concluded a big study published in March in the journal Annals of Internal Medicine. How could this be? The very cornerstone of dietary advice for generations has been that the saturated fats in butter, cheese and red meat should be avoided because they clog our arteries. For many diet-conscious Americans, it is simply second nature to opt for chicken over sirloin, canola oil over butter.
The new study’s conclusion shouldn’t surprise anyone familiar with modern nutritional science, however. The fact is, there has never been solid evidence for the idea that these fats cause disease. We only believe this to be the case because nutrition policy has been derailed over the past half-century by a mixture of personal ambition, bad science, politics and bias.
Our distrust of saturated fat can be traced back to the 1950s, to a man named Ancel Benjamin Keys, a scientist at the University of Minnesota. Dr. Keys was formidably persuasive and, through sheer force of will, rose to the top of the nutrition world — even gracing the cover of Time magazine — for relentlessly championing the idea that saturated fats raise cholesterol and, as a result, cause heart attacks.
[…]
Critics have pointed out that Dr. Keys violated several basic scientific norms in his study. For one, he didn’t choose countries randomly but instead selected only those likely to prove his beliefs, including Yugoslavia, Finland and Italy. Excluded were France, land of the famously healthy omelet eater, as well as other countries where people consumed a lot of fat yet didn’t suffer from high rates of heart disease, such as Switzerland, Sweden and West Germany. The study’s star subjects — upon whom much of our current understanding of the Mediterranean diet is based — were peasants from Crete, islanders who tilled their fields well into old age and who appeared to eat very little meat or cheese.
As it turns out, Dr. Keys visited Crete during an unrepresentative period of extreme hardship after World War II. Furthermore, he made the mistake of measuring the islanders’ diet partly during Lent, when they were forgoing meat and cheese. Dr. Keys therefore undercounted their consumption of saturated fat. Also, due to problems with the surveys, he ended up relying on data from just a few dozen men — far from the representative sample of 655 that he had initially selected. These flaws weren’t revealed until much later, in a 2002 paper by scientists investigating the work on Crete — but by then, the misimpression left by his erroneous data had become international dogma.