Posted something at the work blog today about these apps that help you do things you previously did with low-tech means, like assembling grocery lists. One of the comments praised a grocery app that gave you turn-by-turn instructions in your store. I never, ever want to hear my phone say “You have arrived at frozen breaded chicken patties.” The idea of people walking through a store, pushing a cart, staring at the screen to see where the coffee is located — as opposed to looking up for the word COFFEE — is the sort of thing from a comedic dystopia. Then: story in the WSJ the other day about someone else starting a service that delivers groceries to your house. The predicate for the business: “no one likes to go grocery shopping.”
I love to go grocery shopping. I went grocery shopping tonight; hit four stores in 90 minutes. Explain to me how it is possible to have an understanding of modern American culture without going to the grocery store. Someone who grocery-shops weekly has a better grasp on our civilization than somoene who spends four years getting a doctorate in Marketing. If they offer such things. I suspect that anyone interested in marketing gets out there and markets as soon as possible, and a doctorate would be useful only for teaching other people about Marketing, which you’ve never done, but studied.
It’s like Journalism school. Saying you understand Journalism because you went to Journalism school is like saying you have a command of the basics of Dentistry because you used a pencil to black out the teeth in a picture of someone’s head.
James Lileks, The Bleat, 2015-01-15.
February 15, 2016
QotD: Staying in touch with the everyday
November 23, 2015
Do you have a smartphone? Do you watch TV? You might want to reconsider that combination
At The Register, Iain Thomson explains a new sneaky way for unscrupulous companies to snag your personal data without your knowledge or consent:
Earlier this week the Center for Democracy and Technology (CDT) warned that an Indian firm called SilverPush has technology that allows adverts to ping inaudible commands to smartphones and tablets.
Now someone has reverse-engineered the code and published it for everyone to check.
SilverPush’s software kit can be baked into apps, and is designed to pick up near-ultrasonic sounds embedded in, say, a TV, radio or web browser advert. These signals, in the range of 18kHz to 19.95kHz, are too high pitched for most humans to hear, but can be decoded by software.
An application that uses SilverPush’s code can pick up these messages from the phone or tablet’s builtin microphone, and be directed to send information such as the handheld’s IMEI number, location, operating system version, and potentially the identity of the owner, to the application’s backend servers.
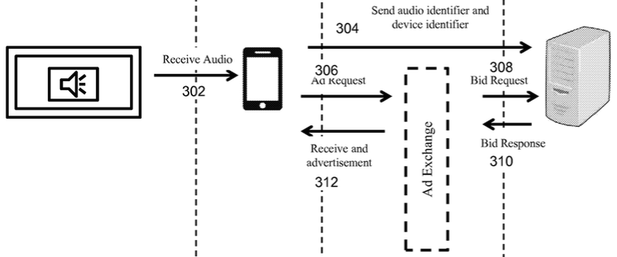
Imagine sitting in front of the telly with your smartphone nearby. An advert comes on during the show you’re watching, and it has a SilverPush ultrasonic message embedded in it. This is picked up by an app on your mobile, which pings a media network with information about you, and could even display followup ads and links on your handheld.
How it works … the transfer of sound-encoded information from a TV to a phone to a backend server
“This kind of technology is fundamentally surreptitious in that it doesn’t require consent; if it did require it then the number of users would drop,” Joe Hall, chief technologist at CDT told The Register on Thursday. “It lacks the ability to have consumers say that they don’t want this and not be associated by the software.”
Hall pointed out that very few of the applications that include the SilverPush SDK tell users about it, so there was no informed consent. This makes such software technically illegal in Europe and possibly in the US.
November 22, 2015
The Problem with Time & Timezones – Computerphile
Published on 30 Dec 2013
A web app that works out how many seconds ago something happened. How hard can coding that be? Tom Scott explains how time twists and turns like a twisty-turny thing. It’s not to be trifled with!
H/T to Jeremy for the link.
November 18, 2015
ESR on “Hieratic documentation”
Eric S. Raymond explains how technical documentation can manage the difficult task of being both demonstrably complete and technically correct and yet totally fail to meet the needs of the real audience:
I was using “hieratic” in a sense like this:
hieratic, adj. Of computer documentation, impenetrable because the author never sees outside his own intimate knowledge of the subject and is therefore unable to identify or meet the expository needs of newcomers. It might as well be written in hieroglyphics.
Hieratic documentation can be all of complete, correct, and nearly useless at the same time. I think we need this word to distinguish subtle disasters like the waf book – or most of the NTP documentation before I got at it – from the more obvious disasters of documentation that is incorrect, incomplete, or poorly written simply considered as expository prose.
November 17, 2015
July 28, 2015
QotD: Master Foo and the Hardware Designer
On one occasion, as Master Foo was traveling to a conference with a few of his senior disciples, he was accosted by a hardware designer.
The hardware designer said: “It is rumored that you are a great programmer. How many lines of code do you write per year?”
Master Foo replied with a question: “How many square inches of silicon do you lay out per year?”
“Why…we hardware designers never measure our work in that way,” the man said.
“And why not?” Master Foo inquired.
“If we did so,” the hardware designer replied, “we would be tempted to design chips so large that they cannot be fabricated – and, if they were fabricated, their overwhelming complexity would make it be impossible to generate proper test vectors for them.”
Master Foo smiled, and bowed to the hardware designer.
In that moment, the hardware designer achieved enlightenment.
Eric S. Raymond, “Master Foo and the Hardware Designer”, Armed and Dangerous, 2014-08-26.
June 25, 2015
QotD: Religion as a user interface for reality
I was raised as a Methodist and I was a believer until the age of eleven. Then I lost faith and became an annoying atheist for decades. In recent years I’ve come to see religion as a valid user interface to reality. The so-called “truth” of the universe is irrelevant because our tiny brains aren’t equipped to understand it anyway.
Our human understanding of reality is like describing an elephant to a space alien by saying an elephant is grey. That is not nearly enough detail. And you have no way to know if the alien perceives color the same way you do. After enduring your inadequate explanation of the elephant, the alien would understand as much about elephants as humans understand about reality.
In the software world, user interfaces keep human perceptions comfortably away from the underlying reality of zeroes and ones that would be incomprehensible to most of us. And the zeroes and ones keep us away from the underlying reality of the chip architecture. And that begs a further question: What the heck is an electron and why does it do what it does? And so on. We use software, but we don’t truly understand it at any deep level. We only know what the software is doing for us at the moment.
Religion is similar to software, and it doesn’t matter which religion you pick. What matters is that the user interface of religious practice “works” in some sense. The same is true if you are a non-believer and your filter on life is science alone. What matters to you is that your worldview works in some consistent fashion.
Scott Adams, “The User Interface to Reality”, The Scott Adams Blog, 2014-07-15.
June 22, 2015
Are software APIs covered by copyright?
At Techdirt, Mike Masnick looks at a recent Supreme Court case that asks that very question:
The Obama administration made a really dangerous and ignorant argument to the Supreme Court yesterday, which could have an insanely damaging impact on innovation — and it appears to be because Solicitor General Donald Verrilli (yes, the MPAA’s old top lawyer) is absolutely clueless about some rather basic concepts concerning programming. That the government would file such an ignorant brief with the Supreme Court is profoundly embarrassing. It makes such basic technological and legal errors that it may be the epitome of government malfeasance in a legal issue.
We’ve written a few times about the important copyright question at the heart of the Oracle v. Google case (which started as a side show to the rest of the case): are software APIs covered by copyright. What’s kind of amazing is that the way you think about this issue seems to turn on a simple question: do you actually understand how programming and software work or not? If you don’t understand, then you think it’s obvious that APIs are covered by copyright. If you do understand, you recognize that APIs are more or less a recipe — instructions on how to connect — and thus you recognize how incredibly stupid it would be to claim that’s covered by copyright. Just as stupid as claiming that the layout of a program’s pulldown menus can be covered by copyright.
The judge in the district court, William Alsup, actually learned to code Java to help him better understand the issues. And then wrote such a detailed ruling on the issue that it seemed obvious that he was writing it for the judges who’d be handling the appeal, rather than for the parties in the case.
April 28, 2015
Fever dream meets DOOM
Ever have one of those fever dreams where you’re moving through the terrain of a video game? Want to recreate that experience for some reason? You’ll want to download Doomdream:
Ever play a video game so often that it shows up in your dreams?
That’s the idea behind Doomdream, an interactive experience created by Ian MacLarty to simulate what his own dreams look like after he’s been playing the classic 1993 shooter Doom all day.
Although there are no enemies, no combat or really any plot, it generates a labyrinth of pixelated gray tunnels and bloody stalagmites for you to wander in forever, recreating the nightmare of so many players who got lost in the purgatory of Doom‘s looping levels, searching fruitlessly for an exit sign.

H/T to BoingBoing for the image and story.
March 11, 2015
“Some of our contractors worked a ridiculous amount of genitalia into the background”
I’d expect some legal action is pending over this little contracting embarrassment for Undead Labs:
Undead Lab’s State of Decay became a cult hit when it released back in 2013. Last year, the developer announced State of Decay: Year One Survival Edition. This updated iteration packs in previously released DLC along with a 1080p graphical overhaul. And once the visuals became clearer, developer Undead Labs realized their contracted help for the game hid an abundance of phalluses in the game.
While working on State of Decay, Undead Labs hired contractors to help build some of the backgrounds. For reasons unknown, those contractors scattered a collage of genitalia across the backgrounds. However, the original version of the game was a low enough resolution that the naughty bits flew under the testing radar.
“Some of our contractors worked a ridiculous amount of genitalia into the background,” says Geoffrey Card, senior designer at Undead Labs in an interview with XBLA Fans.
H/T to John Ryan for the link.
February 9, 2015
Admiral Grace Hopper – the programmer who logged the very first real “bug”
Not all women can code … but neither can all men. Pretending that because all women can’t code means no women can code is an exercise of idiots that is easily dismissed by the very existence of Admiral Grace Hopper, USN:

The First “Computer Bug” Moth found trapped between points at Relay #70, Panel F, of the Mark II Aiken Relay Calculator while it was being tested at Harvard University, 9 September 1947. The operators affixed the moth to the computer log, with the entry: “First actual case of bug being found”. (The term “debugging” already existed; thus, finding an actual bug was an amusing occurrence.) In 1988, the log, with the moth still taped by the entry, was in the Naval Surface Warfare Center Computer Museum at Dahlgren, Virginia, which erroneously dated it 9 September 1945. The Smithsonian Institute’s National Museum of American History and other sources have the correct date of 9 September 1947 (Object ID: 1994.0191.01). The Harvard Mark II computer was not complete until the summer of 1947.
January 21, 2015
Napping
James Lileks takes a nap. It therefore (of course) provides the basis of a “Bleat” posting:
Another item of no surprise to any readers of this site is my enjoyment of, and insistence upon, and devotion to, difficult sentence structures. Also naps. I love naps. Didn’t use to; then we had a child. At first I napped on the floor, thinking it Spartan and manly, but eventually I saw the case for sleeping on a surface that did not leave flat indentations on my skill if I slept for more than 20 minutes. I don’t believe in napping on the sofa, Dagwood style; I don’t believe in napping while reclining in a chair. There’s a reason we sleep in beds. No one ever says “I don’t know how much sleep I’ll get tonight, so maybe I’d better sit in a chair and see how it works.” Bed. The humidifier for white noise. Phone on Airplane Mode. Set the alarm, and see you later.
It’s never occurred to me to study my naps, or chart them, or pick them apart for quality. There are good naps and bad ones. There are short naps that leave you refreshed, and short ones that leave you groggy. Long ones that seem to add a year to your life, and long ones that make you feel as though you emerged from a bog of tar. To be fair, long naps never leave me logy. Short naps can make me feel angry, because they weren’t longer naps.
But. I read a review for an app called Power Nap HQ, and it seemed interesting: it took nap data, based on your movements. You entered how much time you wanted to sleep, set a backup alarm, chose a sequence of sounds, and laid it next to you. It would report back on your movements, indicating the depth of the nap, and it would also record any abrupt sounds you made. Nicely designed, too. A buck. Bought it.
Calibrated the device, set all the options, and pressed the button to start the nap. Laid it next to me.
Got itchy. Dry skin. Scratched a little, and wondered if this would register on the device. This was the signal for my upper lip to report in as “slightly chapped,” requiring more minor motion, and I thought I might be confusing the app, which thinks this is light sleep. Or perhaps it doesn’t take any motion seriously until I’m inert for a long period of time. So I laid still.
Then I thought: now it’s going to think I’m asleep.
This nap wasn’t working out very well. You start to think about napping, napping doesn’t happen. You start to wait for the between-two-worlds moment when you’re aware that you’re having a dream, or are thinking of something you certainly did start but grew out of something you’d already forgotten, then the moment never comes. But the next thing I knew I was awake.
Sort of. Half awake. The alarm had not gone off, so I had not reached the desired quantity of sleep. I was up because my body was done with the noon ration of Diet Lime Coke, and wished to offload it. This I did, wondering how the app would read my absence. It would detect the motion, then the absence of motion, then motion, then – providing I got back to sleep – the absence of motion. I did what a man’s gotta do, then returned to bed to complete the nap. Fell back asleep. No dreams.
Woke, and thought: damn, I beat the alarm. Must be close. If I have one superpower, it is the ability to gauge the passage of time; if I knew what time it was 35 minutes ago, I can tell you what time it is now within a minute or so. This extends to naps: if I wake before the alarm, I usually know what the time will be. I laid there, waking, considering how the rest of the day would play out, then realized that the app would interpret my motionlessness as sleep. THE DATA WOULD BE IMPRECISE.
So I picked up the phone to see how long I’d actually slept.
I had overslept by 40 minutes.
The alarm had not gone off. The backup alarm had not gone off. It had not collected data. Other than that, best dollar I ever spent. Now I can remove it from my phone and sleep without worries.
January 14, 2015
British PM’s latest technological brain fart
Cory Doctorow explains why David Cameron’s proposals are not just dumb, but doubleplus-dumb:
What David Cameron thinks he’s saying is, “We will command all the software creators we can reach to introduce back-doors into their tools for us.” There are enormous problems with this: there’s no back door that only lets good guys go through it. If your Whatsapp or Google Hangouts has a deliberately introduced flaw in it, then foreign spies, criminals, crooked police (like those who fed sensitive information to the tabloids who were implicated in the hacking scandal — and like the high-level police who secretly worked for organised crime for years), and criminals will eventually discover this vulnerability. They — and not just the security services — will be able to use it to intercept all of our communications. That includes things like the pictures of your kids in your bath that you send to your parents to the trade secrets you send to your co-workers.
But this is just for starters. David Cameron doesn’t understand technology very well, so he doesn’t actually know what he’s asking for.
For David Cameron’s proposal to work, he will need to stop Britons from installing software that comes from software creators who are out of his jurisdiction. The very best in secure communications are already free/open source projects, maintained by thousands of independent programmers around the world. They are widely available, and thanks to things like cryptographic signing, it is possible to download these packages from any server in the world (not just big ones like Github) and verify, with a very high degree of confidence, that the software you’ve downloaded hasn’t been tampered with.
[…]
This, then, is what David Cameron is proposing:
* All Britons’ communications must be easy for criminals, voyeurs and foreign spies to intercept
* Any firms within reach of the UK government must be banned from producing secure software
* All major code repositories, such as Github and Sourceforge, must be blocked
* Search engines must not answer queries about web-pages that carry secure software
* Virtually all academic security work in the UK must cease — security research must only take place in proprietary research environments where there is no onus to publish one’s findings, such as industry R&D and the security services
* All packets in and out of the country, and within the country, must be subject to Chinese-style deep-packet inspection and any packets that appear to originate from secure software must be dropped
* Existing walled gardens (like Ios and games consoles) must be ordered to ban their users from installing secure software
* Anyone visiting the country from abroad must have their smartphones held at the border until they leave
* Proprietary operating system vendors (Microsoft and Apple) must be ordered to redesign their operating systems as walled gardens that only allow users to run software from an app store, which will not sell or give secure software to Britons
* Free/open source operating systems — that power the energy, banking, ecommerce, and infrastructure sectors — must be banned outright
David Cameron will say that he doesn’t want to do any of this. He’ll say that he can implement weaker versions of it — say, only blocking some “notorious” sites that carry secure software. But anything less than the programme above will have no material effect on the ability of criminals to carry on perfectly secret conversations that “we cannot read”. If any commodity PC or jailbroken phone can run any of the world’s most popular communications applications, then “bad guys” will just use them. Jailbreaking an OS isn’t hard. Downloading an app isn’t hard. Stopping people from running code they want to run is — and what’s more, it puts the whole nation — individuals and industry — in terrible jeopardy.
December 27, 2014
ESR on the origins of open source theory
Eric S. Raymond acknowledges the strong influence of evolutionary psychology on the development of open source theory:
Yesterday I realized, quite a few years after I should have, that I have never identified in public where I got the seed of the idea that I developed into the modern economic theory of open-source software – that is, how open-source “altruism” could be explained as an emergent result of selfish incentives felt by individuals. So here is some credit where credit is due.
Now, in general it should be obvious that I owed a huge debt to thinkers in the classical-liberal tradition, from Adam Smith down to F. A. Hayek and Ayn Rand. The really clueful might also notice some connection to Robert Trivers’s theory of reciprocal altruism under natural selection and Robert Axelrod’s work on tit-for-tat interactions and the evolution of cooperation.
These were all significant; they gave me the conceptual toolkit I could apply successfully once I’d had my initial insight. But there’s a missing piece – where my initial breakthrough insight came from, the moment when I realized I could apply all those tools.
The seed was in the seminal 1992 anthology The Adapted Mind: Evolutionary Psychology and the Generation of Culture. That was full of brilliant work; it laid the foundations of evolutionary psychology and is still worth a read.
(I note as an interesting aside that reading science fiction did an excellent job of preparing me for the central ideas of evolutionary psychology. What we might call “hard adaptationism” – the search for explanations of social behavior in evolution under selection – has been a central theme in SF since the 1940s, well before even the first wave of academic sociobiological thinking in the early 1970s and, I suspect, strongly influencing that wave. It is implicit in, as a leading example, much of Robert Heinlein’s work.)
The specific paper that changed my life was this one: Two Nonhuman Primate Models for the Evolution of Human Food Sharing: Chimpanzees and Callitrichids by W.C. McGrew and Anna T.C. Feistner.
In it, the authors explained food sharing as a hedge against variance. Basically, foods that can be gathered reliably were not shared; high-value food that could only be obtained unreliably was shared.
The authors went on to observe that in human hunter-gatherer cultures a similar pattern obtains: gathered foods (for which the calorie/nutrient value is a smooth function of effort invested) are not typically shared, whereas hunted foods (high variance of outcome in relation to effort) are shared. Reciprocal altruism is a hedge against uncertainty of outcomes.
November 30, 2014
Medium.com goes all “Rathergate” on a 1970s LEGO letter
I managed to miss the initial controversy about a typographical hoax that might not have been so hoax-y:
According to the website of the Independent newspaper, LEGO UK has verified the 1970s ‘letter to parents’ that was widely tweeted last weekend and almost as widely dismissed as fake. Business as usual in the Twittersphere — but there are some lessons here about dating type.
‘The urge to create is equally strong in all children. Boys and girls.’ It’s a sentiment from the 1970s that’s never been more relevant. Or was it?
Those of us who produce or handle documents for a living will often glance at an example and have an immediate opinion on whether it’s real or fake. That first instinct is worth holding on to, because it comes from the brain’s evolved ability to reach a quick conclusion from a whole bunch of subtle clues before your conscious awareness catches up. It’s OK to be inside the nearest cave getting your breath back when you start asking yourself what kind of snake.
But sometimes you will flinch at shadows. Why did this document strike us as wrong when it wasn’t?
First, because the type is badly set in exactly the way early consumer DTP apps, and word processor apps to this day (notably Microsoft Word), set type badly — at least without the intervention of skilled users. I started typesetting on an Atari ST, the poor man’s Mac, in 1987. The first desktop publishing program for that platform was newly released, running under Digital Research’s GEM operating system. It came with a version of Times New Roman, and almost nothing else. Me and badly set Times have history.
In the LEGO document, the kerning of the headline is lumpy and the word spacing excessive. The ‘T’ seems out of alignment with the left margin, even after allowing for a lack of optical adjustment. The paragraph indent on the body text has been applied from the start, contrary to modern British typesetting practice; the first line should be full-out. The leading (vertical space between lines of text) is not quite enough for comfort, more appropriate to a dense newspaper column than this short blurb.
There’s also an error in the copy: ‘dolls houses’ needs an apostrophe. Either before or after the last letter of ‘dolls’ would be fine, depending on whether you think you mean a house for a doll or a house for dolls. But it definitely needs to be possessive.
It wasn’t just that the type looked careless. It was that it stank of the careless use of tools that shouldn’t have been available to its creators.



