Scott Alexander on the Safe Uncertainty Fallacy, which is particularly apt in artificial intelligence research these days:
The Safe Uncertainty Fallacy goes:
- The situation is completely uncertain. We can’t predict anything about it. We have literally no idea how it could go.
- Therefore, it’ll be fine.
You’re not missing anything. It’s not supposed to make sense; that’s why it’s a fallacy.
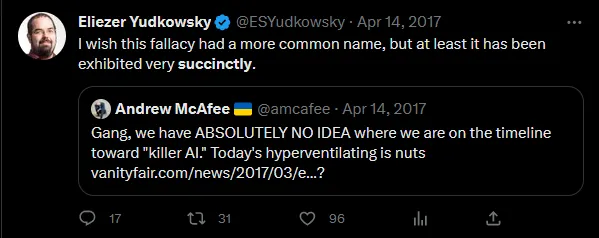
For years, people used the Safe Uncertainty Fallacy on AI timelines:
Eliezer didn’t realize that at our level, you can just name fallacies.
Since 2017, AI has moved faster than most people expected; GPT-4 sort of qualifies as an AGI, the kind of AI most people were saying was decades away. When you have ABSOLUTELY NO IDEA when something will happen, sometimes the answer turns out to be “soon”.
Now Tyler Cowen of Marginal Revolution tries his hand at this argument. We have absolutely no idea how AI will go, it’s radically uncertain:
No matter how positive or negative the overall calculus of cost and benefit, AI is very likely to overturn most of our apple carts, most of all for the so-called chattering classes.
The reality is that no one at the beginning of the printing press had any real idea of the changes it would bring. No one at the beginning of the fossil fuel era had much of an idea of the changes it would bring. No one is good at predicting the longer-term or even medium-term outcomes of these radical technological changes (we can do the short term, albeit imperfectly). No one. Not you, not Eliezer, not Sam Altman, and not your next door neighbor.
How well did people predict the final impacts of the printing press? How well did people predict the final impacts of fire? We even have an expression “playing with fire.” Yet it is, on net, a good thing we proceeded with the deployment of fire (“Fire? You can’t do that! Everything will burn! You can kill people with fire! All of them! What if someone yells “fire” in a crowded theater!?”).
Therefore, it’ll be fine:
I am a bit distressed each time I read an account of a person “arguing himself” or “arguing herself” into existential risk from AI being a major concern. No one can foresee those futures! Once you keep up the arguing, you also are talking yourself into an illusion of predictability. Since it is easier to destroy than create, once you start considering the future in a tabula rasa way, the longer you talk about it, the more pessimistic you will become. It will be harder and harder to see how everything hangs together, whereas the argument that destruction is imminent is easy by comparison. The case for destruction is so much more readily articulable — “boom!” Yet at some point your inner Hayekian (Popperian?) has to take over and pull you away from those concerns. (Especially when you hear a nine-part argument based upon eight new conceptual categories that were first discussed on LessWrong eleven years ago.) Existential risk from AI is indeed a distant possibility, just like every other future you might be trying to imagine. All the possibilities are distant, I cannot stress that enough. The mere fact that AGI risk can be put on a par with those other also distant possibilities simply should not impress you very much.
So we should take the plunge. If someone is obsessively arguing about the details of AI technology today, and the arguments on LessWrong from eleven years ago, they won’t see this. Don’t be suckered into taking their bait.
Look. It may well be fine. I said before my chance of existential risk from AI is 33%; that means I think there’s a 66% chance it won’t happen. In most futures, we get through okay, and Tyler gently ribs me for being silly.
Don’t let him. Even if AI is the best thing that ever happens and never does anything wrong and from this point forward never even shows racial bias or hallucinates another citation ever again, I will stick to my position that the Safe Uncertainty Fallacy is a bad argument.