Well, if by indigenous we mean “the minimally admixed descendants of the first humans to live in a place”, we can be pretty confident about the Polynesians, the Icelanders, and the British in Bermuda. Beyond that, probably also those Amazonian populations with substantial Population Y ancestry and some of the speakers of non-Pama–Nyungan languages in northern Australia? The African pygmies and Khoisan speakers of click languages who escaped the Bantu expansion have a decent claim, but given the wealth of hominin fossils in Africa it seems pretty likely that most of their ancestors displaced someone. Certainly many North American groups did; the “skraelings” whom the Norse encountered in Newfoundland were probably the Dorset, who within a few hundred years were completely replaced by the Thule culture, ancestors of the modern Inuit. (Ironically, the people who drove the Norse out of Vinland might have been better off if they’d stayed; they could hardly have done worse.)
Well, if by indigenous we mean “the minimally admixed descendants of the first humans to live in a place”, we can be pretty confident about the Polynesians, the Icelanders, and the British in Bermuda. Beyond that, probably also those Amazonian populations with substantial Population Y ancestry and some of the speakers of non-Pama–Nyungan languages in northern Australia? The African pygmies and Khoisan speakers of click languages who escaped the Bantu expansion have a decent claim, but given the wealth of hominin fossils in Africa it seems pretty likely that most of their ancestors displaced someone. Certainly many North American groups did; the “skraelings” whom the Norse encountered in Newfoundland were probably the Dorset, who within a few hundred years were completely replaced by the Thule culture, ancestors of the modern Inuit. (Ironically, the people who drove the Norse out of Vinland might have been better off if they’d stayed; they could hardly have done worse.)
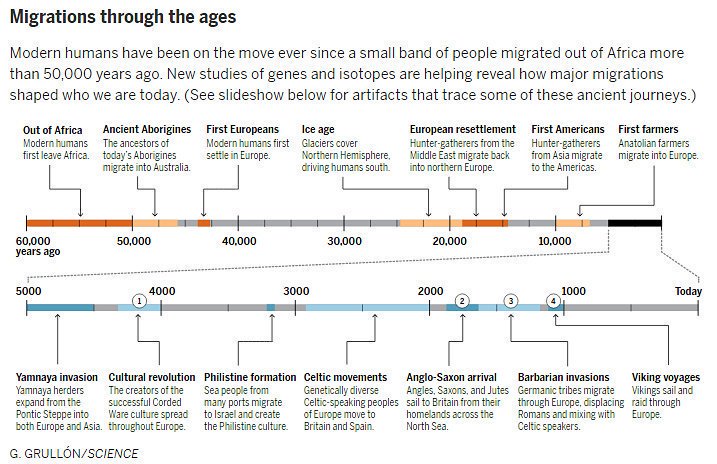
But of course this is pedantic nitpicking (my speciality), because legally “indigenous” means “descended from the people who were there before European colonialism”: the Inuit are “indigenous” because they were in Newfoundland and Greenland when Martin Frobisher showed up, regardless of the fact that they had only arrived from western Alaska about five hundred years earlier. Indigineity in practice is not a factual claim, it’s a political one, based on the idea that the movements, mixtures, and wholesale destructions of populations since 1500 are qualitatively different from earlier ones. But the only real difference I see, aside from them being more recent, is that they were often less thorough — in large part because they were more recent. In many parts of the world, the Europeans were encountering dense populations of agriculturalists who had already moved into the area, killed or displaced the hunter-gatherers who lived there, and settled down. For instance, there’s a lot of French and English spoken in sub-Saharan Africa, but it hasn’t displaced the Bantu languages like they displaced the click languages. Spanish has made greater inroads in Central and South America, but there’s still a lot more pre-colonial ancestry among people there than there is pre-Bantu ancestry in Africa. I think these analogies work, because as far as I can tell the colonization of North America and Australia look a lot like the Early European Farmer and Bantu expansions (technologically advanced agriculturalists show up and replace pretty much everyone, genetically and culturally), while the colonization of Central and South America looks more like the Yamnaya expansion into Europe (a bunch of men show up, introduce exciting new disease that destabilizes an agricultural civilization,1 replace the language and heavily influence the culture, but mix with rather than replacing the population).
Some people argue that it makes sense to talk about European colonialism differently than other population expansions because it’s had a unique role in shaping the modern world, but I think that’s historically myopic: the spread of agriculture did far more to change people’s lives, the Yamnaya expansion also had a tremendous impact on the world, and I could go on. And of course the way it’s deployed is pretty disingenuous, because the trendier land acknowledgements become, the more the people being acknowledged start saying, “Well, are you going to give it back?” (Of course they’re not going to give it back.) It comes off as a sort of woke white man’s burden: of course they showed up and killed the people who were already here and took their stuff, but we’re civilized and ought to know better, so only we are blameworthy.
More reasonable, I think, is the idea that (some of) the direct descendants of the winners and losers in this episode of the Way Of The World are still around and still in positions of advantage or disadvantage based on its outcome, so it’s more salient than previous episodes. Even if, a thousand years ago, your ancestors rolled in and destroyed someone else’s culture, it still sucks when some third group shows up and destroys yours. It’s just, you know, a little embarrassing when you’ve spent a few decades couching your post-colonial objections in terms of how mean and unfair it is to do that, and then the aDNA reveals your own population’s past …
Reich gets into this a bit in his chapter on India, where it’s pretty clear that the archaeological and genetic evidence all point to a bunch of Indo-Iranian bros with steppe ancestry and chariots rolling down into the Indus Valley and replacing basically all the Y chromosomes, but his Indian coauthors (who had provided the DNA samples) didn’t want to imply that substantial Indian ancestry came from outside India. (In the end, the paper got written without speculating on the origins of the Ancestral North Indians and merely describing their similarity to other groups with steppe ancestry.) Being autochthonous is clearly very important to many peoples’ identities, in a way that’s hard to wrap your head around as an American or northern European: Americans because blah blah nation of immigrants blah, obviously, but a lot of northern European stories about ethnogenesis (particularly from the French, Germans, and English) draw heavily on historical Germanic tribal migrations and the notion of descent (at least in part) from invading conquerors.
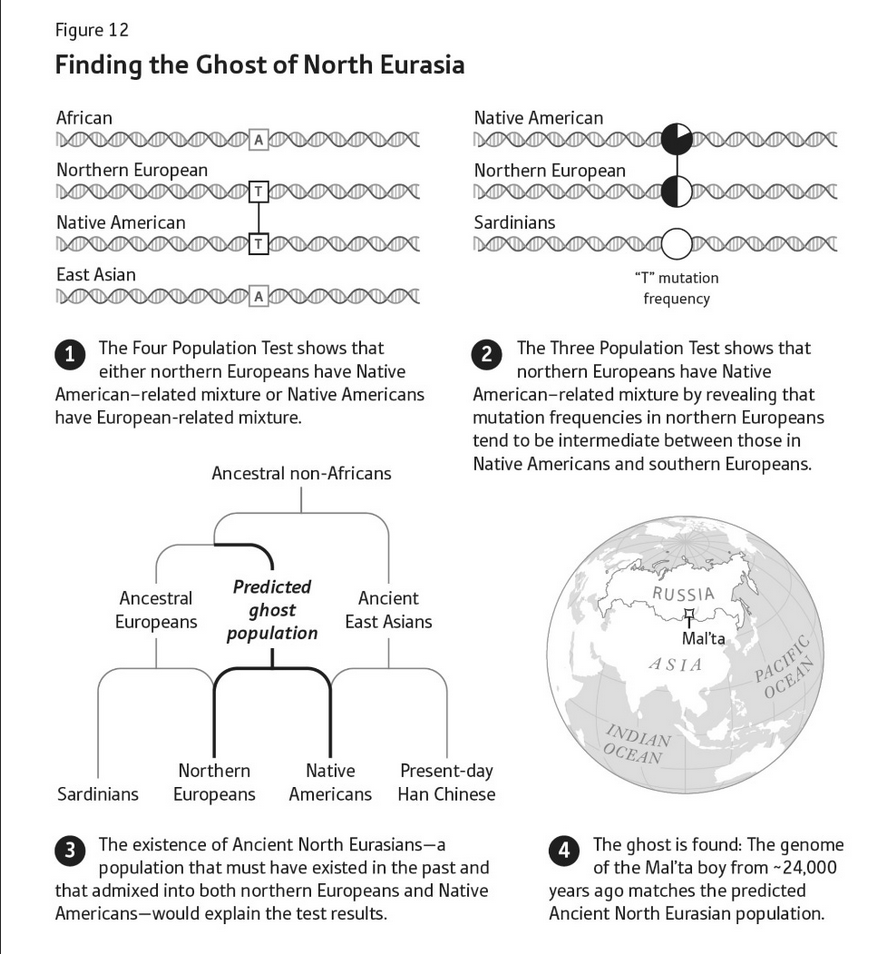
One underlying theme in the book — a theme Reich doesn’t explicitly draw out but which really intrigued me — is the tension between theory and data in our attempts to understand the world. You wrote above about those two paradigms to explain the spread of prehistoric cultures, which the lingo terms “migrationism” (people moved into their neighbors’ territory and took their pots with them) and “diffusionism”2 (people had cool pots and their neighbors copied them), and which archaeologists tended to adopt for reasons that had as much to do with politics and ideology as with the actual facts on (in!) the ground. And you’re right that in most cases where we now have aDNA evidence, the migrationists were correct — in the case of the Yamnaya, most modern migrationists didn’t go nearly far enough — but it’s worth pointing out that all those 19th century Germans who got so excited about looking for the Proto-Indo-European Urheimat were just as driven by ideology as the 21st century Germans who resigned as Reich’s coauthors on a 2015 article where they thought the conclusions were too close to the work of Gustaf Kossinna (d. 1931), whose ideas had been popular under the Nazis. (They didn’t think the conclusions were incorrect, mind you, they just didn’t want to be associated with them.) But on the other hand, you need a theory to tell you where and how to look; you can’t just be a phenomenological petri dish waiting for some datum to hit you. This is sort of the Popperian story of How Science Works, but it’s more complex because there are all kinds of extra-scientific implications to the theories we construct around our data.
The migrationist/diffusionist debate is mostly settled, but it turns out there’s another issue looming where data and theory collide: the more we know about the structure and history of various populations, the more we realize that we should expect to find what Reich calls “substantial average biological differences” between them. A lot of these differences aren’t going to be along axes we think have moral implications — “people with Northern European ancestry are more likely to be tall” or “people with Tibetan ancestry tend to be better at functioning at high altitudes” isn’t a fraught claim. (Plus, it’s not clear that all the differences we’ve observed so far are because one population is uniformly better: many could be explained by greater variation within one population. Are people with West African ancestry overrepresented among sprinters because they’re 0.8 SD better at sprinting, or because the 33% higher genetic diversity among West Africans compared to people without recent African ancestry means you get more really good sprinters and more really bad ones?) But there are a lot of behavioral and cognitive traits where genes obviously play some role, but which we also feel are morally weighty — intelligence is the most obvious example, but impulsivity and the ability to delay gratification are also heritable, and there are probably lots of others. Reich is adorably optimistic about all this, especially for a book written in 2018, and suggests that it shouldn’t be a problem to simultaneously (1) recognize that members of Population A are statistically likely to be better at some thing than members of Population B, and (2) treat members of all populations as individuals and give them opportunities to succeed in all walks of life to the best of their personal abilities, whether the result of genetic predisposition or hard work. And I agree that this is a laudable goal! But for inspiration on how our society can both recognize average differences and enable individual achievement, Reich suggests we turn to our successes in doing this for … sex differences! Womp womp.
Jane Psmith and John Psmith, “JOINT REVIEW: Who We Are and How We Got Here, by David Reich”, Mr. and Mrs. Psmith’s Bookshelf, 2023-05-29.
1. aDNA works for microbes too, and it looks like Y. pestis, the plague, came from the steppe with the Yamnaya. It didn’t yet have the mutation that causes buboes, but the pneumonic version of the disease is plenty deadly, especially to the Early European Farmers who didn’t have any protection against it. In fact, as far as we can tell, in all of human history there have only been four unique introductions of plague from its natural reservoirs in the Central Asian steppe: the one that came with or slightly preceded the Yamnaya expansion around 5kya, the Plague of Justinian, the Black Death, and an outbreak that began in Yunnan in 1855. The waves of plague that wracked Europe throughout the medieval and early modern periods were just new pulses of the strain that had caused Black Death. Johannes Krause gets into this a bit in his A Short History of Humanity, which I didn’t actually care for because his treatment of historic pandemics and migrations is so heavily inflected with Current Year concerns, but I haven’t found a better treatment in a book so it’s worth checking it out from the library if you’re interested.
2. I cheated with that “pots not people” line in my earlier email; it usually gets (got?) trotted out not as a bit of epistemological modesty about what the archaeological record is capable of showing, but as a claim that the only movements involved were those of pots, not of people.